By Seminar Information Systems (WS 19/20) | February 7, 2020
Interpretable Neural Networks for Customer Choice Modelling
Haseeb Warsi, Benedict Becker, Veronika Simoncikova
Contents
Introduction
It's no secret that consumers today are faced with more product choices than ever before. While having many choices can be beneficial to a point, eventually it can become overwhelming and consumers may become paralysed in the face of so many options (Iyengar, Lepper, 2000). For this reason, many online, and offline, businesses have created tools and methods to recommend certain products to certain groups of consumers, thereby reducing the number of products a consumer has to consider. Of course, recommendation is no easy task, and much has been written about the best method to use (Koren et al., 2009).
Many recommendation algorithms focus on latent variables that seek to describe underlying user preferences and item attributes. Most, however, do not include external factors such as price or seasonality. From a retailer's perspective, it would be ideal to know the maximum price each customer is willing to pay for each item. Retailers could then potentially have personalized per-item prices for each consumer, which would maximize the retailer's revenue.
One way this could be achieved is if all products were unpurchasable by default, or simply more expensive than anyone’s willingness to pay (WTP). Then all customers entering the store receive a coupon for all the products they came to buy, that is exactly equal to the difference between their maximum WTP and the item price. Though unrealistic, this example illustrates how one could achieve personalized pricing, as actively displaying different prices to each individual customer in a store is unfeasible, and if possible, would lead to customer dissatisfaction.
We begin our blog with an overview of user preference estimation techniques currently used in industry, namely Poisson Factorization and Exponential Family Embeddings. Then we detail a model combining and further extending the features of these two models, a sequential probabilistic model called SHOPPER. Finally, we proceed to build our own predictive model based on SHOPPER (Ruiz et al., 2017) using the TensorFlow architecture, with the goal of predicting consumer choices. The focus will be placed particularly on the grocery industry. We
Literature review
What are the current trends in retail marketing to maximize stores’ revenue? To name a few, firms perform demand-sensitive pricing through estimating price elasticity (Skyscanner, 2019), or identify which of their (and their competitors’) products are substitutes or complements to allow for product differentiation. This is commonly performed in the industry through econometric models such as regression or various forms of matrix factorization. Further, marketing departments aim to capture customer heterogeneity by splitting customers into a number of clusters and developing products or services customized for these segments (e.g. pet owners, vegetarians). For such tasks analysts may opt for clustering techniques, such as principal components analysis (Jolliffe, 2011), k-means clustering (Lloyd, 1982), or discrete choice models, including questionnaire-based conjoint analysis. Traditional choice models require that products are restricted to a small subset of items, or grouped into a handful of categories, in order to make computations feasible (Nevo, 1998). One step beyond clustering is individual personalization - serving each customer according to their needs. This will be our aim in the grocery store setting. So what are the current state-of-the-art models for personalized item predictions?
Poisson factorization
Widely used in E-commerce settings, Hierarchical Poisson factorization (HPF) (Gopolan et al., 2015) captures user-to-item interaction, extracting user preferences for recommendation of previously unpurchased products through past purchases of other similar customers. The mathematics underlying this model are straightforward: users’ preferences are Gamma distributed based on their past activity (number of shopping trips) and items’ attributes are Gamma distributed based on their popularity (number of purchases). The user-item interaction is expressed in the rating (either a points scale, such as 1-5 stars, or binary dummy for purchase), which is Poisson distributed according to the user’s preference and item’s attribute. As a simple example, imagine a customer who has only bought vegetables in her five previous shopping trips (activity). This customer’s preference would thus be classified as vegetarian. On the other hand, the shop has a variety of frequently bought (popular) vegetables (which is an attribute of those items). As other customers with the preference “vegetarian” have bought asparagus, the resulting “rating” will be high, and thus this customer would receive a recommendation to buy asparagus.
Exponential Family Embeddings
An alternative to Poisson factorization is the collection of models known as Exponential family embeddings (EFE). It stems from methods created for natural language processing, such as word embeddings (Mikolov et al., 2013), but can be extended to other highly-relational datasets. It is composed of individual terms (originally words, in our case grocery items) that make up a corpus (dictionary or store inventory) and are mutually bound in a context (sentence or a shopping basket) via conditional probability. This link is the probability that a specific item is in this particular basket given all the other items in the same basket, and comes from an exponential distribution, such as Poisson for discrete and Gaussian for real-valued data points. The objective is to maximize these conditional probabilities of the whole corpus, which creates shared embeddings for each term. Through these latent embeddings, we can calculate similarity (and dissimilarity) as the cosine distance between the embedding vectors and thus represent how similar (or disimilar) items are to each other. Moreover, “Poisson embeddings can capture important econometric concepts, such as items that tend not to occur together but occur in the same contexts (substitutes) and items that co-occur, but never one without the other (complements)” (Rudolph et al, 2016).
These state-of-the-art models have their shortcomings; neither of these capture price effects and seasonality patterns. SHOPPER attempts to build on these two models, by combining the item-to-item interaction of EFE and user preferences of HPF, and also accounting for price effects and seasonality.
Shopper - What is it and how does it work?

The SHOPPER algorithm (Ruiz et al., 2017) is a sequential probabilistic model for market baskets. SHOPPER models how customers place items in their basket when shopping for groceries, taking various factors into account, including seasonal effects, personal preferences, price sensitivities and item-to-item interactions. SHOPPER imposes a structure on customer behaviour and assumes customers behave according to the Random Utility Model, a model founded in economic principles.
SHOPPER posits that a customer walks into the store and sequentially chooses each item to be placed in the basket. The customer chooses each item based on personal preferences, price, seasonality and overall item popularity. As each item is placed into the basket, the customer then takes the current products in the basket into account when deciding on the next product. One can imagine a typical shopping trip, where the customer goes in with an intent to buy a specific item, e.g. cheese, and later decides to spontaneously purchase complementary products, such as wine and crackers. Although the customer initially had no intention of purchasing wine and crackers, the presence of cheese increased the attractiveness of the complementary products. SHOPPER generates latent variables to model these factors, estimates an overall utility value for each shopping trip and calculates a probability of observing a set of items in a given basket.
The basics of the model can be summarized with the following 5 equations:
$$\psi_{tc} = \lambda_{c} + \theta_{ut}^T \alpha_{c} - \gamma_{ut}^T \beta_{c} log(r_{tc}) + \delta_{wt}^T \mu_{c} $$
$$\Psi(c, y_{t, i-1}) = \psi_{tc} + \rho_{c}^T(\frac{1}{i-1} \displaystyle\sum_{j=1}^{i-1} \alpha_{y_{tj}} )$$
$$max \space U_{t,c}(y_{t, i-1}) = \Psi(c, y_{t, i-1}) + \epsilon_{t,c} $$
$$p(y_{ti} = c | \mathbf{y}_{t, i-1}) = \frac{exp\{\Psi(c, \mathbf{y}_{t, i-1})\}}{\displaystyle \sum_{c' \notin y_{t, i-1}}exp\{\Psi(c', \mathbf{y}_{t, i-1})\} } $$
$$\widetilde{U}_t(\mathcal{Y_t}) = \displaystyle\sum_{c \in \mathcal{Y_t}} \psi_{tc} + \frac{1}{|\mathcal{Y_t}| - 1} \displaystyle\sum_{(c, c') \in \mathcal{Y_t} \times \mathcal{Y_t}:c'\neq c} v_{c',c}$$
Although daunting at first, the model can be broken down into smaller pieces to fully understand it. From a conceptual point of view, SHOPPER assumes that a consumer seeks to maximize the utility received from their basket each shopping trip (equation 5). They do this by selecting an item from all of the available items in the store (equation 4). The product most likely to be chosen by the shopper is the one that provides her with the highest utility (equation 3). The utility function can be described as a log-linear function with latent variables representing: item popularity, user preferences, price sensitivities, seasonal effects and item-item interactions (equations 1 and 2). The following sections will delve further into detail for each equation.
Equation 1 (Latent Variables)¶
$$\psi_{tc} = \lambda_{c} + \theta_{ut}^T \alpha_{c} - \gamma_{ut}^T \beta_{c} log(r_{tc}) + \delta_{wt}^T \mu_{c} $$
Equation 1 represents the utility a customer gets from item $c$ in trip $t$. The above equation can be divided into several smaller portions.
Item Popularity : $\lambda_{c}$ can be thought of as representing a latent intercept term that captures overall item popularity. In this case, the more popular an item is, the higher the value of this variable should be.
User Preferences : To get a more accurate utility estimate, SHOPPER creates a per-user latent vector $\theta_{u}$, along with a per-item latent $\alpha_c$. By taking the dot product of the two vectors we get per-item preferences for each shopper. A larger value indicates a higher preference a shopper has for a certain item.
Price Sensitivities : SHOPPER posits that each user has an individualized price elasticity for each item. To estimate these elasticities SHOPPER generates a new set of per-user latent vectors, $\gamma_{ut}$, and a new set of per-item latent vectors, $\beta_{c}$. $\gamma_{ut}^T \beta_{c}$ then represents the price elasticity for each user for each item. $\gamma_{ut}^T \beta_{c}$ is restricted to be positive, so that $- \gamma_{ut}^T \beta_{c} log(r_{tc})$ remains negative, where $r_{tc}$ is the normalized price of the product. This is to ensure that shopper utility will decrease as price increases, meaning shoppers prefer to have the same good at lower prices. SHOPPER normalizes item prices by dividing the item's price by its mean weekly price. This brings all prices to a comparable scale so that larger prices don’t over-influence the training.
Seasonality : Certain items sell more depending on the time of year, e.g. chocolate at Easter, partly because demand increases, but also because of sales implemented by the store. Neglecting seasonality means that price sensitivity variables could include seasonal effects. SHOPPER deals with this by adding the per-week item interaction effect $\delta_{wt}^T \mu_{c}$, where $\delta_{w}$ represents the per-week latent vectors and $\mu_{c}$ represents a new set of per-item latent vectors. A higher scalar product means that item adds more to shopper utility in that week than items with a lower scalar product for that week. Including $\mu_{c}$ also allows for correlated seasonal effects across items, i.e. two products that are purchased in the same season should have similar latent vectors. In this model, we could expect chocolate and eggs to have a higher value during Easter than any other time in the year.
Equation 2 (Item-Item Interactions)¶
$$\Psi(c, y_{t, i-1}) = \psi_{tc} + \rho_{c}^T(\frac{1}{i-1} \displaystyle\sum_{j=1}^{i-1} \alpha_{y_{tj}} )$$
Equation 1 calculates the utility a customer receives from a specific item $c$ by itself. However, this ignores important item-to-item interaction effects. For example, if a customer has already placed crackers in their basket, then the utility obtained by buying cheese would be greater than if the cheese was purchased without crackers. To model these item to item interactions, SHOPPER introduces the term $\rho_c$.
If we consider two items $c$ and $c'$, then $\rho_c$ represents the interaction effects of product $c$ and $c'$. Using the item attribute vector, $\alpha_{c'}$ estimated earlier in equation 1 we can estimate the complementary and substitution effects of different products. If $\rho_{c}^T \alpha_{c'}$ is large, then the presence of item $c'$ in the basket increases the benefit choosing item $c$. These two products would be considered complements. Conversely, when $\rho_{c}^T \alpha_{c'}$ is negative, we can interpret these items as substitutes. Even if the latent item vectors are similar, the two products can still be substitutes, i.e. crackers and crispbread (Knäckebrot).
In the SHOPPER model, when the customer is deciding whether to put item $c$ in the basket, they do not consider the item-to-item interaction of every single item individually. Instead SHOPPER takes the average value of the latent item vectors of the products already in the basket and calculates the scaler product with $\rho_{c}$. The scaling factor $ \frac{1}{(i - 1)}$ captures the idea that in larger baskets each individual item has a smaller effect on the addition of a new product in the basket.
Additionally, the utility function is additive in the other items in the basket, meaning SHOPPER assumes that item interactions within the basket are linear. This assumption may not be completely realistic. Conversely, by using a neural network architecture, there is no prior assumption placed on the behaviour of item to item interactions. Both linear and non-linear interactions can be captured.
Equation 3 & 4 (Utility and Choice Probabilities)¶
From equations 1 and 2 we calculate the term $\Psi(c, y_{t, i-1})$, which is interpreted as the utility a customer receives from item $c$, given the week, price, and other items in the basket. The customer's problem then becomes:
$$max \space U_{t,c}(y_{t, i-1}) = \Psi(c, y_{t, i-1}) + \epsilon_{t,c} $$
Those familiar with discrete choice modelling will quickly recognize the above formula as a Random Utlity Model (Mcfadden, 1978). Upon entering the store, the customer is presented with a set of alternatives they must choose from. The customer chooses the alternative that maximizes her utility, i.e. if item $c$ generates a higher utility than item $c'$, the customer chooses item $c$. The full utility $U$ is known to the customer, but has a random component that is not observable by an outsider (for example how hungry they are during the shopping trip). In SHOPPER, $\Psi(c, y_{t, i-1})$ represents the deterministic portion of the customer's utility, the portion that can be modelled, and $\epsilon_{t,c}$ represents the random portion of utility. See the Appendix for a further explanation of the Random Utility Model.
Using the derivation from Train (2009) and the assumption of i.i.d error terms that follow a Gumbel distribution, we can show that the probability of a shopper choosing item $c$ can be described using a softmax function.
$$p(y_{ti} = c | \mathbf{y}_{t, i-1}) = \frac{exp\{\Psi(c, \mathbf{y}_{t, i-1})\}}{\displaystyle \sum_{c' \notin y_{t, i-1}}exp\{\Psi(c', \mathbf{y}_{t, i-1})\} }$$

Equation 5 (Putting it All Together)¶
We have now seen the decision making process of our customer when choosing a single product, but the overall goal of the shopping trip is to maximize the utility of the entire basket. In this case, the shopper only cares about the items that are in their basket at the end of the trip and not necessarily in what order they were placed in.
$$\widetilde{U}_t(\mathcal{Y_t}) = \displaystyle\sum_{c \in \mathcal{Y_t}} \psi_{tc} + \frac{1}{|\mathcal{Y_t}| - 1} \displaystyle\sum_{(c, c') \in \mathcal{Y_t} \times \mathcal{Y_t}:c'\neq c} v_{c',c}$$From the above equation, we see that the customer chooses items such that the unordered set of items $\mathcal{Y_t}$ maximizes utility. $\displaystyle\sum_{c \in \mathcal{Y_t}} \psi_{tc}$ represents the sum of the utilities gained from each item in the basket. $\frac{1}{|\mathcal{Y_t}| - 1} \displaystyle\sum_{(c, c') \in \mathcal{Y_t} \times \mathcal{Y_t}:c'\neq c} v_{c',c}$ represents the utility gained from item-item interactions in the basket.
Probabilities of Unordered Baskets¶
Equation 5 from above actually represents the utility a shopper gains from the unordered set of items in her basket, but our softmax function from earlier (equation 4) gives us the probability of an ordered basket.
The probability of an ordered basket can be calculated by multiplying the individual choice probabilities with each other. For example, the probability of getting the basket $(bread, eggs, milk)$ equals $p(bread| ) \times p(eggs| bread) \times p(milk| bread, eggs)$. In general, it can be written as:
$$p(\mathbf{y}_t | \rho, \alpha) = \displaystyle \prod_{i=1}^{n_t} p(y_{ti}| \mathbf{y}_{t, i-1}, \rho, \alpha) $$
where $n_t$ represents the last item in the basket for that trip. However, in most offline real-world datasets, the order in which items are added to the basket is not observed. To account for this, SHOPPER calculates the likelihood of an unordered set of items $\mathcal{Y}_t$, by summing over all the possible orderings. In our small example above, this corresponds to:
$$p(\{bread, eggs, milk\}) = p((bread, eggs, milk)) + p((eggs, bread, milk)) + p((eggs, milk, bread)) + ...$$
For only three items, we have to consider six different probabilities. As the basket size grows to $n$ items, we then have to sum over $n!$ probabilities, which can very quickly become intractable. The probability of an unordered basket can be generalized as:
$$ p(\mathcal{Y}_t | \rho, \alpha) = \displaystyle \sum_{\pi}p(\mathbf{y}_{t, \pi}| \rho, \alpha) $$
where $\pi$ is a permutation of the items in the basket. SHOPPER then generates its latent variables to maximize the estimated log of this probability. The closer the log-likelihood is to zero, the better the latent variables describe the observed data.
How is SHOPPER different¶
As we have seen, SHOPPER combines modern machine learning techniques with economic theory to create a generative model that takes user preferences, seasonal factors, and price elasticities into account. SHOPPER uses the Random Utility Model to model customer behaviour and matrix factorization to generate user and item embeddings. By combining these two techniques, SHOPPER can generate shopper preferences for shopping data. One potential point of concern is the scale of data SHOPPER can handle. SHOPPER was trained on just under 6 million item purchases from 3206 unique customers and 5590 unique items, but a large store from a large grocery chain can be expected to have significantly more items and customers.
Matrix Factorization
Generating Latent Variables
Now that we have seen how SHOPPER works conceptually, we can look into how the latent variables are actually generated.
One option of creating latent variables is to simply create a one-hot encoded matrix. We could create a vector for each shopper that has a 1 for each item they have bought, and a zero for products they did not buy. By repeating this process for all shoppers, we create our one-hot encoded customer-item matrix. The rows of our matrix can actually be considered an embedding for that shopper, as we have now converted a shopper's purchases into a numerical vector. Similarly, the columns of our matrix can be considered to be the item embedding, as we now see which shoppers purchased that item. The following shows an example of what a one-hot encoded matrix would look like:
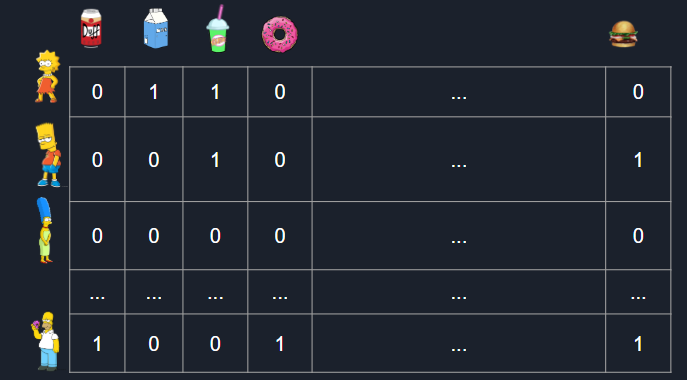
We can see that it is easy to summarize across shoppers or products, but it is difficult to see any underlying patterns among users or products. A large number of shoppers and products can also cause memory problems. The dimensions of the matrix are $ \# \ unique \ shoppers * \# \ unique \ items$ and much of the matrix is also sparse, meaning most entries are 0. This is because most shoppers do not purchase or even consider all of the unique products for sale. For our small example, this is not a problem but larger datasets with thousands of unique shoppers and thousands of unique products require a higher memory capacity. It also becomes difficult to optimize our model using this structure, since we would have to update weights for each individual item-shopper combination. It is also impossible to estimate a coefficient value from shoppers with little to no purchases at all.
To solve this problem we turn to matrix factorization (MF). MF posits that there is a set of latent variables (unobservable features) that describe each shopper and each item, such that when multiplied together the resulting product is our observed shopper-item matrix. In our small example, we believe that there are 5 latent variables that can accurately describe shoppers and items. Therefore we create two matrices $Shoppers$ and $Items$, that hold our shoppers' latent variables and items' latent variables, respectively. To begin with, we initialize the matrices randomly. An example can be seen below, where $l_i$ represents latent variable $i$:

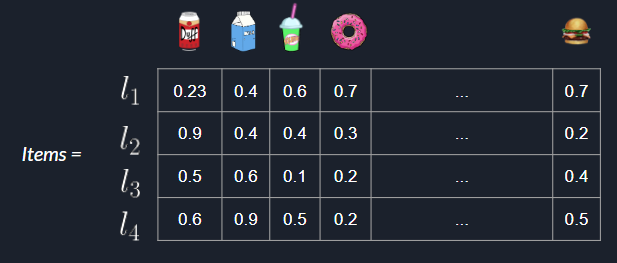
The rows of our $Shoppers$ matrix represent latent shopper variables and the columns of our $Items$ matrix represent latent item variables. We need to estimate our latent variables such that $Shoppers \cdot Items $ is equal to our observed shopper-item matrix. To see if our factorization is doing well, we define an error function. In traditional matrix factorization, an error term such as the matrix norm or mean squared error is used to calculate the error. However, the authors of SHOPPER define a variational inference algorithm that optimizes the factorization based on the log-likelihood of baskets described earlier. The algorithm is out of the scope of this post, but interested readers can see it here. Those interested in a more in-depth explanation of matrix factorization can follow this link.
Our Task
We will now replicate the SHOPPER model by using maximum likeliehood estimation with stochastic gradient descent as an optimiztion technique. The trick here is to turn SHOPPER, a generative model, into a discriminative model, one that optimizes by making a prediction. We will take a deeper look into the unique challenges of this problem and our corresponding results.
Data Exploration and Preparation
For this task, we will use a dataset of purchases made between April 2015 and March 2017 from an unspecified grocery chain in Germany. The information available to us is the user ID, shopping basket ID, product name, category and sub-category of the product, price and date of purchase.
The best selling products include the bottle deposit (“Pfand”) and shopping bags. These do not have much value for our predictive model, as in the prices for these are set by law and hence coupons are not applicable. Therefore we preemptively remove these two product subcategories. Without these, the best-sellers were newspapers, bananas and bread rolls.
To get a sense of our shoppers' habits, we first take a look at the distribution of the number of items in each basket. We would like to know how many items are in a shopper's basket, on average, for modelling purposes later. From the chart below, we see that, with a few notable outliers, almost all shoppers had less than 40 products in their baskets, with 12 products on average.
import seaborn as sns
import matplotlib.pyplot as plt
sns.distplot(df_concat['prods_in_basket'])
# histogram of number of products in baskets

A vast majority of products are sold at low price points - most of the store's revenue comes from products cheaper than 5 Euros, and in fact, most products cost between 50 cents and 1 Euro. This fact is specific to grocery stores.
n, bins, patches = plt.hist(df['price'], bins=[0,0.5,1,1.5,2,2.5,3,3.5,4,4.5,5], density = True)
plt.title("Sales by price in low price points", fontsize=18)
plt.xlabel("Price in Euros", fontsize = 15)
plt.ylabel("Share of products bought", fontsize = 15)
plt.show()

Some days are more popular for shopping than others. If you prefer to do your groceries in peace and quiet, consider going on Tuesday; if however you enjoy the rush and crowds, Saturday is your (and everyone else's) day to visit. Note that in Germany, stores are closed on Sundays!
There is not as much variation when it comes to months. Still, the most revenue is usually made in April, when Germans stack up on their favourite asparagus, while in October people rather go trick-or-treating than grocery shopping.
plt.bar(df_by_weekday['dayofweek'],df_by_weekday['shopping_trips']/sum(df_by_weekday['shopping_trips']))
plt.ylabel('Share of weekly visits')
plt.title('Visits by Day of week', fontsize=15)
plt.show()

plt.bar(df_by_month['month'],df_by_month['shopping_trips']/sum(df_by_month['shopping_trips']))
plt.ylabel('Share of total visits')
plt.title('Visits by Month', fontsize=15)
plt.show()

Although there is little difference in the number of products sold between individual months, which products are sold differs immensely. The product sub-categories with the greatest degree of seasonality entail, unsurprisingly, Easter marzipan, Christmas chocolate figures, figs and other dried fruit, stem vegetables (including asparagus), venison, poultry and nuts.
df_subcat_by_month_range = pd.DataFrame( ((df_subcat_by_month['items_bought'].max(level=0) - df_subcat_by_month['items_bought'].min(level=0)) / df_subcat_by_month['items_bought'].mean(level=0) ), )
df_subcat_by_month2 = df_subcat_by_month_range.sort_values(by='items_bought',ascending=False).reset_index()
df_subcat_by_month2.rename(columns={'items_bought':'relative_change_between_months'},inplace=True)
df_subcat_by_month2.head(10)
# relative_change_between_months = 4 means that the difference between the best-selling and worst-selling month for the category is 4 times higher than the mean sales
Before we can feed our data to any model, we need to further clean our data. First, we drop rows that have no value for item name or user ID, as we always need to be able to identify the product and the customer in each purchase. Then, since we are predicting only which items the customer is going to buy, regardless of quantity, we disregard all duplicate entries in the same basket. Likewise, the product category “other”, that contains items not typical for groceries such as socks and sweaters, is removed.
In addition, we make two assumptions about general shopping trends. First, we assume that good personal recommendations can only be made for loyal customers, so we restrict our dataset to customers who have visited the store at least 10 times, dropping infrequent visitors. Secondly, to be able to extract reasonable item-to-item interactions, we allow only baskets with at least two items, and at most 40 items.
Since we are turning a generative model into one that makes predictions, we need to make further adjustments to our dateset. SHOPPER fits its latent variable estimates to the observed shopping baskets data and minimizes the log likelihood error when training. However, in order for our model to work, we must give it a prediction task on which to optimize.
One problem that occurs when facing such a task with actual shopping data is that we can only see products that were bought by customers, and not products that were considered but not bought. However, when building a model based on shopper preferences, we require products that were not bought, in order to accurately generate these preferences.
A solution for this problem is to add products that are not bought into the data. Training on this allows the model to distinguish which products a shopper is more likely to buy and those she will not buy, thereby generating the preferences of that shopper. Such a process needs some assumptions and to factor in the specifics of grocery shopping in order to sample new products into the data.
The "most correct" way for us to model shopper choices would be to treat the problem as a discrete choice problem. We would have to calculate the probability that a specific item was chosen by the shopper over all available products. This would essentially become a softmax function over 35 000 items in our case. Since this is not technically feasible, we use a simplification inspired by the authors of word2vec (Mikolov et al. 2013).
Instead of considering one item against all other items, we instead sample items that the shopper did not place in their basket, assign them a "bought" value of 0, and predict whether or not the shopper bought the item. The problem then becomes a binary choice problem, "bought" or "not bought", over bought items and our sampled not-bought items. This speeds up our calculations and should also generate robust results, as seen in other applications (Mikolov et al, 2013, Titsias, 2016)
For our sampling procedure, we make the following assumptions:
- A shopper considers products from the same subcategories as the items in her basket. For example, if the customer buys spaghetti she also considered penne or maybe spaghetti from a different brand on the shelf.
- The price of the product that was not bought will be equal to the most frequent price the particular product was bought at in the respective week and year
These two assumptions lead to a certain expectation about the shopping habits of customers. We assume that if a shopper has bought a product, then she must have at least seen other products from the same sub-category and chosen not to purchase them. For our model we sample one not-bought item for every bought item. This gives us an equal representation of bought and not-bought products, so our model training is not overwhlemed by one class. It can be debated if the customer only considers one other product for every product she bought. In general, customers most likely consider more than one item when shopping. The optimal number of not-bought samples should allow the model to accurately estimate preferences, but not be overwhlemed by the majority class. That is an area for further discussion.
Below we describe our sampling procedure for not-bought items:
- Group all products by subcategory name, year, and week.
- Group shopper purchases into baskets, by grouping on user id and basket hash.
- Randomly sample one item from the full group that is in the same subcategory as the item in the shopper's basket, and not already in the shopping basket.
- Fill in the rows of the new products with data of the remaining columns from the original product except for price.
- Calculate the most frequent price at which a particular product was sold in a particular week and year. For prices that are unavailable we use the previous week's price, and if still unavailable, we use the following week's price (Molnar et al., 2008).
- Mark sampled products as not bought, by assigning a bought value of 0.
We first create groups for all products which were available in a subcategory for each week and year combination. We will use these groups to sample unpurchased products into the dataset.
# Step 1
# create groups of products by subcategory, week and year
groups = df_concat.groupby(['year','week','subcategory_name']).apply(lambda x: x['article_text'].unique())
groups.head()
Next we group the products a user bought in one shopping trip into a basket, which contains all the products she bought in this trip.
# Step 2
# create baskets for each user containing the products of a particular shopping trip
baskets = total_filter.groupby(['user_id','basket_hash']).apply(lambda x: x['article_text'].unique())
baskets
We then take the difference between the group of all products and the basket of products of a certain shopping trip. From this difference, we randomly select one product from the same subcategory as a product that was bought. Thereby creating a new product which was not bought by this customer in her shopping trip, but was available for purchase in the same sub-category.
# Step 3
# randomly taking a product from the same subcategory as a product that was bought
import random
new_rows = pd.Series([random.choice(list(set(groups[(x.year, x.week, x.subcategory_name)]).difference(set(baskets[(x.user_id, x.basket_hash)])))) for x in total_filter.itertuples() if len(list(set(groups[(x.year, x.week, x.subcategory_name)]).difference(set(baskets[(x.user_id, x.basket_hash)])))) > 0])
Next we fill in the other columns of the new product with data of the remaining columns from the original bought item except for price.
# Step 4
# fill the rows of the new products with data of the remaining columns
# from the original product except for price
new_sample = pd.DataFrame({'basket_hash': [x.basket_hash for x in total_filter.itertuples() if len(list(set(groups[(x.year, x.week, x.subcategory_name)]).difference(set(baskets[(x.user_id, x.basket_hash)])))) > 0],
'article_text': new_rows,
'user_id': [x.user_id for x in total_filter.itertuples() if len(list(set(groups[(x.year, x.week, x.subcategory_name)]).difference(set(baskets[(x.user_id, x.basket_hash)])))) > 0],
'week': [x.week for x in total_filter.itertuples() if len(list(set(groups[(x.year, x.week, x.subcategory_name)]).difference(set(baskets[(x.user_id, x.basket_hash)])))) > 0],
'year': [x.year for x in total_filter.itertuples() if len(list(set(groups[(x.year, x.week, x.subcategory_name)]).difference(set(baskets[(x.user_id, x.basket_hash)])))) > 0],
'category_name': [x.category_name for x in total_filter.itertuples() if len(list(set(groups[(x.year, x.week, x.subcategory_name)]).difference(set(baskets[(x.user_id, x.basket_hash)])))) > 0],
'subcategory_name': [x.subcategory_name for x in total_filter.itertuples() if len(list(set(groups[(x.year, x.week, x.subcategory_name)]).difference(set(baskets[(x.user_id, x.basket_hash)])))) > 0]})
The only value that is still missing is the price of the product. In our data there are lots of different prices for the same products, depending on season, coupons or other outside factors. Similar to the groups of products we create a list where we can find the most frequent price at which a particular product was sold in a respective week and year. As there can still be a week where we do not have a price for a certain product we use forward and backward fill. Therefore we will always get a price for our new products.
There can be instances where prices are higher or lower depending on the day in a certain week. In the data there are sometimes differences in price even on the same day. However, this sampling approach generates reliable data that can be seen as the majority price of a certain product at which the customer did not buy the product.
Imputing the prices was a necessary step for us, since we did not have a full list of product prices to simply look up from. We only had the prices for sold products. However, grocery stores should have a price list for all products available, so this last step may not be necessary, depending on the data availability.
df_prices = df_concat[['article_text', 'price', 'day']]
df_prices['day'] = pd.to_datetime(df_prices['day'])
df_prices['week'] = df_prices['day'].dt.week
df_prices['year'] = df_prices['day'].dt.year
def top_value_count(x):
return x.value_counts().idxmax()
# Step 5
# calculate the most frequent price at which a particular product
# was sold in a respective week and year
prices_top_freq = df_prices.groupby(['year','week', 'article_text'])['price']
prices = prices_top_freq.apply(top_value_count).reset_index()
# add the prices for our new products by merging with the most frequent prices
new_sample2 = pd.merge(new_sample, prices, how = 'left', on = ['year', 'week', 'article_text'])
new_sample2['price'] = new_sample2.groupby('article_text')['price'].transform(lambda x: x.fillna(method = 'ffill'))
new_sample2['price'] = new_sample2.groupby('article_text')['price'].transform(lambda x: x.fillna(method = 'bfill'))
These sampled products now just have to be marked that they are not-bought items in comparison to the original items that were bought and then put together with the original data to create our new dataset.
# Step 6
# products are sampled to add to data and were not bought
new_sample2['bought'] = 0
new_sample2 = new_sample2[['basket_hash', 'article_text', 'user_id', 'price', 'category_name','subcategory_name', 'bought', 'week', 'year']]
We then concatenate the sampled not-bought products and bought products into one dataframe, reseting the index so that they are distributed within the bought products and are not appended in one big chunk.
# putting bought and sampled not bought products into one dataframe
final_df = total_filter.append(new_sample2).sort_index().reset_index(drop=True)
Now that we have our bought and not bought products, we need to add one additional column. We are also estimating item-item interactions so we include an additional column that includes a list of all the other items that were purchased in by the shopper for that specific trip. We wait until after not-bought products have been sampled to also accurately estimate the item-item interation effects. This way we have products that the shopper did not buy, given their entire basket.
# add other items from basket into seperate column as a list
final_df['other_basket_prods'] = pd.Series([list(set(baskets[(x.user_id, x.basket_hash)]).difference(x.article_text)) for x in final_df.itertuples() ])
Our dataset is now complete and prepared, so let's look at modelling.
Modelling
As seen in SHOPPER our approach is to build a model for personalized shopping recommendations. Our goal is to translate the SHOPPER model into the TensorFlow framework and see if that can yield accurate purchase predictions and useful embeddings. Most of the maths behind SHOPPER can be found in our approach as well. This can be seen for example with the way our embeddings are calculated. Later we will pick that thought up again and see what formula from SHOPPER goes where in our model architecture.
Our model takes five inputs: shopper ID, item name, other products in the basket, week and price of the item. To begin, we create embeddings for each of our inputs. The embeddings can be seen as latent vector representations, and the dot product of two of these embeddings then gives us the combination contribution to the overall utility. One of our dot products is multiplied by our price variable to give us the price sensitivity. We then sum all of our different dot products to obtain an estimate of utility, which is then put through a sigmoid function to calculate our probabilities of purchase.
The formulas from SHOPPER that we want to use for our model are equations 1 and 2 containing latent variables and item-item interactions:
$$\psi_{tc} = \lambda_{c} + \theta_{ut}^T \alpha_{c} - \gamma_{ut}^T \beta_{c} log(r_{tc}) + \delta_{wt}^T \mu_{c} $$$$\Psi(c, y_{t, i-1}) = \psi_{tc} + \rho_{c}^T(\frac{1}{i-1} \displaystyle\sum_{j=1}^{i-1} \alpha_{y_{tj}} )$$Similar to what we described in the beginning, when we explained the different parts of this formula we will refresh the meaning of the different steps and then show how they are implemented into our model step by step.
The first formula equals the Utility a customer obtains from a specific item $c$ by itself, calculated by summing the Item Popularity, User Preferences, Price Sensitivites and Seasonal Effects.
The second equation takes this Utility and adds the additional utility a customer gets from item-to-item interaction of item $c$ with item $c'$ in trip $t$. Having this in our model allows us to predict the probablilty at which a customer will buy a certain product, taking into account the postive or negative interaction with items that are already in the basket. The higher the item-to-item utility is for an item, $c$, the greater the chance the customer will buy it. These utilities change depending on the other items in her basket.
Model architecture¶
Prior to modelling, we must label encode all of our categorical variables, in order to use them as inputs into our embedding layers.
# creating label encoders for items, users and weeks
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(final_df['article_text'])
final_df['encoded_prods'] = le.transform(final_df['article_text'])
final_df['other_basket_prods_encoded'] = final_df['other_basket_prods'].apply(lambda x : le.transform(x))
le_user = LabelEncoder()
le_user.fit(final_df['user_id'])
final_df['encoded_user'] = le_user.transform(final_df['user_id'])
le_week = LabelEncoder()
le_week.fit(final_df['week'])
final_df['encoded_week'] = le_week.transform(final_df['week'])
We split our data into 80% training and 20% test sets. We elected to use a random split for this problem, as it is testing all possible seasons and holidays.
# splitting the data into train and test
from sklearn import model_selection
X = final_df.drop(["bought", 'basket_hash', 'category_name', 'subcategory_name'], axis = 1)
Y = final_df["bought"]
X_train, X_test, Y_train, Y_test = model_selection.train_test_split(
X, Y, test_size = 0.2, random_state = 42)
Here we bring all of our basket sizes to equal length. Recall, that we limited the maximum size of our baskets to 40 products.
from keras.preprocessing.sequence import pad_sequences
largest_basket = X_train['other_basket_prods_encoded'].apply(lambda x: len(x)).max()
basket_prods_train_pad = pad_sequences(X_train['other_basket_prods_encoded'], maxlen = largest_basket + 1, padding = 'post')
basket_prods_test_pad = pad_sequences(X_test['other_basket_prods_encoded'], maxlen = largest_basket + 1, padding = 'post')
basket_prods_train_pad
import keras
from keras.layers import Input, Embedding, Dot, Reshape, Dense, , multiply, average, add
from keras.models import Model
from keras.optimizers import Adam
Here we define our input variables. We will have five inputs: the shopper ID, the item, the price of the item, the week in which the shopping trip took place, and the other items in the basket. All inputs have a shape of 1, aside from the basket input. This is because baskets can be of varying length, so we leave the dimensions as None, in order to be able to accomodate this.
# defining the inputs for our model user, item, price and week
embedding_size = 100
user_len = len(le_user.classes_) + 1
item_len = len(le.classes_) + 1
week_len = len(le_week.classes_) + 1
user = Input(name = 'user', shape = (1,))
item = Input(name = 'item', shape = (1,))
price = Input(name = 'price', shape = (1,))
week = Input(name = 'week', shape = (1,))
basket = Input(name = 'basket', shape = (None,))
The Item Popularity, $\lambda_{c}$, captures the overall item popularity and will be represented in our model by the item popularity embedding that goes straight into our last add function. It has an embedding dimension of 1.
# creating the first embedding layer for item popularity with embedding size of 1
item_pop = Embedding(name = 'item_pop',
input_dim = item_len,
output_dim = 1)(item)
# Reshape to be a single number (shape will be (None, 1))
item_pop = Reshape(target_shape = (1, ))(item_pop)
Next we implement the User Preferences, $\theta_{ut}^T \alpha_{c}$, as the dot product of the newly created user embedding $\theta_{u}$ and the item embedding $\alpha_c$. We create a shared embedding layer here that will be used for both indiviual items and the embeddings of items in our baskets variable. This is to ensure that the latent representation of an individual item and the latent representation of that same item in a basket remains the same. We specify the argument mask_zero=True to ignore the zeros we added earlier when padding our baskets. We ignore zeros because we do not want to artificially diminish the importance of item-item interactions in smaller baskets.
# creating the embeddings for user and item
# Embedding the user (shape will be (None, 1, embedding_size))
user_embedding = Embedding(name = 'user_embedding',
input_dim = user_len,
output_dim = embedding_size)(user)
# shared item embedding layer for items and baskets
# use mask_zero = True, since we had to pad our baskets with zeros
prod_embed_shared = Embedding(name = 'prod_embed_shared_embedding',
input_dim = item_len,
output_dim = embedding_size,
input_length = None,
mask_zero =True)
# Embedding the product (shape will be (None, 1, embedding_size))
item_embedding = prod_embed_shared(item)
# Merge the layers with a dot product along the second axis
# (shape will be (None, 1, 1))
user_item = Dot(name = 'user_item', axes = 2)([item_embedding, user_embedding])
# Reshape to be a single number (shape will be (None, 1))
user_item = Reshape(target_shape = (1, ))(user_item)
Jumping forward a bit, we consider the term $\rho_{c}^T(\frac{1}{i-1} \displaystyle\sum_{j=1}^{i-1} \alpha_{y_{tj}} )$ from equation 2. We first create a new item-item interaction vector $\rho_{c}$ that captures complementary effects between items. This is multiplied by the term $\displaystyle\sum_{j=1}^{i-1} \alpha_{y_{tj}}$, which is nothing more than the average of the vectors of all the other items in the shopping basket. Note that this $\alpha$ is the same as the $\alpha$ from our previous embedding. This is why we use a shared embedding layer.
# create item to item embedding
item_item_embedding = Embedding(name = 'item_item_embedding',
input_dim = item_len,
output_dim = embedding_size)(item)
# embed each item in a basket
basket_embedding = prod_embed_shared(basket)
# take the average of all item embeddings in a basket
avg_basket_embedding = keras.layers.Lambda(lambda x: keras.backend.mean(x, axis=1))(basket_embedding)
avg_basket_embedding = Reshape(target_shape=(1,embedding_size))(avg_basket_embedding)
# take the dot product of the item and the other items in the basket
# (shape will be (None, 1, 1))
item_basket = Dot(name = 'item_basket', axes = 2)([item_item_embedding, avg_basket_embedding])
# Reshape to be a single number (shape will be (None, 1))
item_basket = Reshape(target_shape = (1,))(item_basket)
We now consider estimating price sensitivities. From the SHOPPER algorithm we have, $\gamma_{ut}^T \beta_{c} log(r_{tc})$. We create new item and user embeddings $\gamma_{ut}$ and $\beta_{c}$. In order to calculate the price elasticity for each user, $\gamma$, for each item, $\beta$, we take the dot product of our two embeddings, resulting in $\gamma_{ut}^T \beta_{c}$. This elasticity then gets multiplied with the price $r_{tc}$ to get the overall price effect on shopper utility.
In this step we varied from SHOPPER as we did not take the log of the normalized price or take the negative. We found our model was able to recognize, on average, that a higher price lowers the probability of purchase for an item. Although, we did have cases where price elasticities were estimated to be positive, which goes against our intuition. In the future we can consider restricting our estimates to negative values only. We also estimated the price effects of each individual item, whereas the authours of SHOPPER normalize prices within categories. We did this to get the most granular price effects possible. This complex embedding structure allows us to have a price sensitivity for every customer and every product.
# Embedding the product (shape will be (None, 1, embedding_size))
item_embedding_price = Embedding(name = 'item_embedding_price',
input_dim = item_len,
output_dim = embedding_size)(item)
# Embedding the user (shape will be (None, 1, embedding_size))
user_embedding_price = Embedding(name = "user_embedding_price",
input_dim = user_len,
output_dim = embedding_size)(user)
# Merge the layers with a dot product along the second axis
# (shape will be (None, 1, 1))
user_item_price = Dot(name = 'user_item_price_dot', axes = 2)([item_embedding_price, user_embedding_price])
# Reshape to be a single number (shape will be (None, 1))
user_item_price = Reshape(target_shape = (1,))(user_item_price)
# multiply price effect by price to get effect on utility
user_item_price = multiply([price, user_item_price], name = 'user_item_price')
Lastly we consider the Seasonality $\delta_{wt}^T \mu_{c}$ which we calculate from a new set of item embeddings $\mu_{c}$ and a set of week embedddings $\delta_{w}$. From these latent vectors we again take the dot product to calculate the Seasonality.
# Embedding the week (shape will be (None, 1, embedding_size))
week_embedding = Embedding(name = 'week_embedding',
input_dim = week_len,
output_dim = embedding_size)(week)
# Embedding the product (shape will be (None, 1, embedding_size))
week_item_embedding = Embedding(name = 'week_item_embedding',
input_dim = item_len,
output_dim = embedding_size)(item)
# Merge the layers with a dot product along the second axis
# (shape will be (None, 1, 1))
week_item = Dot(name = 'week_item', axes = 2)([week_item_embedding, week_embedding])
# Reshape to be a single number (shape will be (None, 1))
week_item = Reshape(target_shape = (1, ))(week_item)
Adding these four effects together gives us the utility of a product $c$ to a costumer $u$ when buying this product for price $r_{tc}$ in week $w$ for a certain trip $t$. This utility will be put into the dense layer and with a sigmoid function we get a probability between 0 and 1 of the customer to buy said product.
# Sum up various dot products to get total utility value
x = keras.layers.add([item_pop, user_item, user_item_price, week_item, item_basket])
# Squash outputs for classification
out = Dense(1, activation = 'sigmoid', name = 'output')(x)
# Define model
model = Model(inputs = [user, item, price, week, basket], outputs = out)
# Compile using specified optimizer and loss
model.compile(optimizer = Adam(lr=0.0002), loss = 'binary_crossentropy',
metrics = ['accuracy'])
print(model.summary())
Putting all of the above steps together leads to the model summary that can be seen in the code above. The graphic below illustrates how the embeddings are interconnected. There, the different embeddings, input layers etc. have different shapes to tell them apart and the individual components of SHOPPER equation 1 and 2 are colorcoded so that it gets easier to track what part goes where.
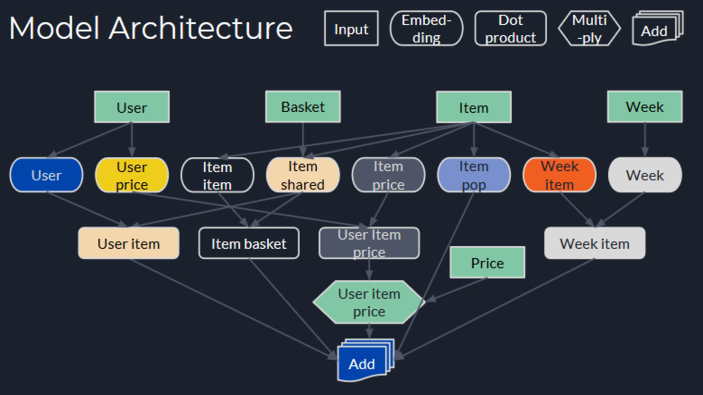
As previously mentioned, when creating the item-price embedding, we varied from SHOPPER as we did not change prices in any way. Therefore we can just add up all the components and feed it to our final activation layer.

story = model.fit({'user': X_train['encoded_user'], 'item': X_train['encoded_prods'], 'price':X_train['price'], 'week': X_train['encoded_week'],
'basket': basket_prods_train_pad},
{'output': Y_train},
epochs=3, verbose=1, validation_split = 0.1, batch_size = 128)
story.history
We train for a small number of epochs with a low learning rate because, during experimentation, we found our model to overfit on the training set very quickly. This is likely because the data is individualized (we are using unique identifiers for users and items). One option to be discussed in future research could be to see the effect of adding a regularization parameter to the loss function.
# make predictions
preds = model.predict({'user': X_test['encoded_user'], 'item': X_test['encoded_prods'], 'price':X_test['price'],
'week':X_test['encoded_week']})
X_test.loc[: , 'bought'] = Y_test
X_test.loc[:,'pred_prob'] = preds
# change probabilities to binary classification
# used cutoff of 0.5, because distribution of 1's and 0's is 50-50
X_test['pred'] = round(X_test['pred_prob'])
Results
After training we take a look at our results. First, we see how the model performed on our prediction task by looking at the ROC and the AUC. We use an AUC score of 0.5 as a naive benchmark, to see if our model is at least better than predicting randomly. Recall that the distribution of 1's and 0's is balanced, due to our previous sampling procedure.
# Python script for confusion matrix creation.
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
actual = X_test['bought']
predicted = X_test['pred']
results = confusion_matrix(actual, predicted)
print('Confusion Matrix :')
print(results)
print('Accuracy Score :',accuracy_score(actual, predicted))
print('Report : ')
print(classification_report(actual, predicted))
def compute_roc(y_true, y_pred, plot=False):
"""
TODO
:param y_true: ground truth
:param y_pred: predictions
:param plot:
:return:
"""
fpr, tpr, _ = roc_curve(y_true, y_pred)
auc_score = auc(fpr, tpr)
if plot:
plt.figure(figsize=(7, 6))
plt.plot(fpr, tpr, color='blue',
label='ROC (AUC = %0.4f)' % auc_score)
plt.legend(loc='lower right')
plt.title("ROC Curve")
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.show()
return fpr, tpr, auc_score
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# plot ROC
compute_roc(X_test['bought'], X_test['pred'], plot=True)

We can clearly see that the model outperforms random guessing. However, as evident from the ROC, the model can correctly distinguish between purchased and unpurchased items at lower thresholds. But, eventually, the model reaches a plateau and can not improve its predictions. We also observed this in the accuracy measure during model training.
Embeddings¶
Item Embeddings
An additional benefit of this model is the embeddings that it generates. These embeddings can give insights into user preferences, seasonal factors and price elasticities. Below we will take a look at the resulting embeddings. First we define a function to extract our embeddings.
def get_model_embeddings(model_name, layer_name, encoder_name):
import numpy as np
import pandas as pd
embeddings = model_name.get_layer(layer_name)
embeddings_weights = embeddings.get_weights()[0]
integer_mapping = {l:i for i, l in enumerate(encoder_name.classes_)}
embeddings_dict = {w:embeddings_weights[idx] for w, idx in integer_mapping.items()}
vectors_df = np.array([v for i, v in embeddings_dict.items()])
names = [i for i, v in embeddings_dict.items()]
vectors_df = pd.DataFrame(data = vectors_df, index = names)
return vectors_df
Since we have over 91 categories to consider, we will look at a small sample of 6 categories to see how our embeddings look.
# extract item embeddings
item_vectors_df = get_model_embeddings(model, 'prod_embed_shared_embedding', le)
item_vectors_df = item_vectors_df.merge(cat_subcat_text_groups, left_index=True, right_on='article_text')
item_vectors_df = item_vectors_df.set_index(['category_name', 'subcategory_name', 'article_text'])
cats_to_consider = ['condiments', 'oil', 'fresh_pasta', 'milk', 'fruits', 'meat_sausages']
item_vectors_df_subset = item_vectors_df.loc[item_vectors_df.index.get_level_values('category_name').isin(cats_to_consider)]
item_vectors_df_subset = item_vectors_df_subset.sort_index(level = 'category_name')
To reduce the number of dimensions, we use a relatively new method of dimensionality reduction called UMAP. UMAP is another dimensionality reduction technique, like T-SNE, but has it's own algorithm. UMAP is much faster and can capture global relationships better (McInnes et al., 2018).
import umap
reducer = umap.UMAP(n_neighbors= 2,
n_components = 2,
min_dist = 0.1,
metric = 'cosine')
viz = reducer.fit_transform(item_vectors_df_subset)
item_embeddings_umap = pd.DataFrame(viz, columns=['dim_1', 'dim_2'], index=item_vectors_df_subset.index).reset_index()
datasource = ColumnDataSource(item_embeddings_umap)
color_mapping = CategoricalColorMapper(factors= [x for x in item_embeddings_umap['category_name'].unique()],
palette=Accent[6])
plot_figure = figure(
title='UMAP projection of the Item Embeddings',
plot_width=800,
plot_height=800,
tools=('pan, wheel_zoom, reset')
)
plot_figure.add_tools(HoverTool(tooltips=[("Label1", "@article_text")]))
plot_figure.circle(
'dim_1',
'dim_2',
source=datasource,
color=dict(field='category_name', transform=color_mapping),
line_alpha=0.6,
fill_alpha=0.6,
size=6
)
show(plot_figure)
With the help of UMAP we can find clusters of products that where bought by similar customers. A very nice example can be found in the bottom left with several lactose free products. We can then, for example, conclude that these customers are lactose intolerant and consider it for our marketing efforts.
Seasonality
Another feature of our model, similar to SHOPPER, is the usage of seasonal effects on shopping preferences. To calculate seasonal effects we take the dot product of our respective item and week embeddings. Below we show the seasonal scores for the week of Easter. The item with the second highest score is an Easter product and we see many more chocolate items with a higher score than other weeks. Our model is able to identify these products that would be in higher demand during Easter, showing that seasonal effects have been picked up by the model.
week_vectors_df = get_model_embeddings(model, 'week_embedding', le_week)
week_item_vectors_df = get_model_embeddings(model, 'week_item_embedding', le)
seasonality = week_vectors_df.dot(week_item_vectors_df.T).T
#easter (lots of easter chocolate show up)
seasonality[12].sort_values(ascending = False)[0:10]
Although it may be fairly obvious that chocolate sells more during Easter, this information can still be of value to retailers. With this knowledge retailers can see which specific items are more likely to be bought than others. They can then avoid printing coupons for seasonal items that are near the top of the list, since shoppers will seek them out anyways. Instead retailers can focus on seasonal products that have a lower score, to induce shoppers to purchase them, and reduce in-store waste.
Price Elasticities
We now consider the price elasticities generated by our model. The goal of generating these is to be able to accurately see the effect price has on the probability of a shopper purchasing a specific item. Using this, a retailer could potentially generate personalized coupons that bring the price of an item down to a consumer's maximum willingness to pay. We test this on our model by taking a shopper and an item, hold all other variables constant, and vary only the price of the item.
user_price_vectors_df = get_model_embeddings(model, 'user_embedding_price', le_user)
item_price_vectors_df = get_model_embeddings(model, 'item_embedding_price', le)
price_elasticities = user_price_vectors_df.dot(item_price_vectors_df.T)
def elasticity_check(user_id, article_text, price, week, basket_hash):
check = pd.DataFrame({'user': le_user.transform([user_id]),
'item': le.transform([article_text]),
'price': [price],
'week':le_week.transform([week]),
'other_basket_prods': [final_df.loc[final_df['basket_hash'] == basket_hash, 'other_basket_prods_encoded'].max()]})
check_pad = pad_sequences(check['other_basket_prods'], maxlen= 40+1, padding='post')
prob = model.predict({'user': check['user'], 'item': check['item'], 'price': check['price'],
'week': check['week'], 'basket': check_pad})
return prob
user_id = 859
item = 'danone activia muesli 4x125g'
price = 2
week = 45
other_items_in_basket = -6102514878161295466
print('Probability of user_id {}'.format(user_id), 'purchasing item {}'.format(item),
'in week {}'.format(week), 'at price {}'.format(price),
'is: {}'.format(elasticity_check(user_id, item, price, week, other_items_in_basket)))
new_price = 1.25
print('Probability of user_id {}'.format(user_id), 'purchasing item {}'.format(item),
'in week {}'.format(week), 'at price {}'.format(new_price),
'is: {}'.format(elasticity_check(user_id, item, new_price, week, other_items_in_basket)))
Our above example shows an example use-case of our model. Consider a grocery retailer who wishes to induce user 859 into purchasing the Danone Activia Muesli pack. The probability of the shopper purchasing the item is 0.07 at a price of 2 euros, which results in an expected revenue of 0.14 euros for the store. Offering the shopper a discount of 0.75 euros increases the probability of purchase to 0.10, which results in an expected revenue of 0.125 euros for the store. In this case, it is not in the store's interest to give the customer a discount, unless the item would go to waste anyways. Grocery items have a relatively short shelf-life compared to other goods, and cannot be sold after their expiry date has passed. Using this method, retailers could encourage shoppers to buy these expiring groceries, as opposed to simply throwing them out.
Discussion¶
Regarding the initial question of designing the coupons that maximize revenue: when the customer enters the store in a given week, we would compute the maximum price this customer is willing to pay (by running the model over the same product but multiple prices and taking the highest price whose probability is still over a certain threshold*), and then print coupons for the products that have highest probabilities of purchase under their maximum price. We can also incorporate other products in the basket in this reasoning: first, the product with the highest probability would be assumed as already being in the basket when computing the second most probable product, then these two would comprise the basket for selection of the third product, and so on. This would be iterated as long as the purchase probability is over a certain threshold. If our model is right, the customer will use all printed coupons during their store visit.
*As the price with highest probability would most certainly be very low, and far from the WTP.
An error may occur in several ways. During the first run of the model, when determining the maximum willingness to pay, the calculated price can be either too high or too low. If too low, the store is losing additional revenue from the price difference, but if it is too high, the customer will not buy at all. As the “sunk” revenue is expected to be generally higher than the potential loss from setting a low price (unless the cost is lower than the customer’s WTP), it is more profitable to minimize the probability of overestimating the WTP, and so the management should choose a high enough probability threshold for price. Recall that in our example, customers may buy a product only with a personalized coupon.
Even if the calculated WTP is right, our model may still misjudge the probability of buying the product. Issuing a coupon for a product that will not be purchased only costs the firm the printing expenses, but not issuing a coupon for a product that would otherwise be bought is again a sunken revenue. Therefore the management should consider to print sufficiently many coupons. Although then psychological barriers could arise, when the customer is pressured to buy too many things and so ends up not purchasing anything, but that is outside the scope of our model.
Areas for Further Research
We now discuss areas for future consideration:
- Number of not-bought samples: It is not immediately clear if we should only sample one unpurchased item for each purchased item. To make the process of customer choice more believable, we could consider more than one “non-bought” product to be sampled for our model. The dataset would thus become imbalanced, but that is the case in real life - the customer “sees” substantially more products than those that she ends up purchasing. How many she actually considers is not clear.
- Order of item placement in basket: Currently, we are assuming that the shopper's basket is full and the item we are predicting on is her final, or "checkout" item. We do this because we do not observe the order in which the customer placed items into her basket. In a perfect world, we would have the order items were placed into the basket available to us and we could then iteratively fill the basket. This would give us a better estimation of item-item interactions.
- "Thinking ahead": We could also incorporate SHOPPER’s “thinking ahead” principle into the model. It posits that customers have an expectation of what they will buy next. This is mostly important for product complements, so when the shopper is buying cereal, she already expects to buy milk as well. This feature would ensure that the customer would receive a coupon for both milk and cereals.
- Daily effects: Our model already accounts for seasonality in terms of weekly effects, but we have also seen an observable divergence in sales between different days of the week. What if individual days also have an effect on which products are purchased? It is not unimaginable, that for example wine is purchased more on a Friday than Wednesday. Therefore we could add one more input and embedding layer for the day of the week
- Brand/Category effects: We assume that our intial user and item embeddings accurately reflect the preferences of a shopper to specific items. However, much research has already been done on the effect of brand and shopper preferences. It could therefore be beneficial for our model to see which shoppers have an affinity for specific brands. Along the same line of thinking, certain shoppers most likely have an affinity for a specific category of products. This would be akin to the nested logit models already prevalent in marketing circles today (Heiss, F., 2002). We could extract this from our overall shopper latent variables and include them seperately.
Other use cases¶
The methods described in this paper could be further extended to other personalized recommendation tasks than couponing in a grocery store. Any other online and offline retail store could make use of this model directly. Outside of retail, movie and song streaming services also do personal recommendations. In this scenario, price could be substituted with the users’ rating (similar to our discussion on Poisson factorization). Overall, this model may be used for any purpose with multiple users, multiple items, seasonality pattern, and a numerical ordering of items.
Conclusion
Our model computes the probability that the given user will purchase a given product at a given price in a given week, given all the other products in her basket. We have shown that it is possible to generate meaningful embeddings and also simulate the effect of price changes on purchase probabilities. We began with discussing current methods of modelling shopper preferences, took a deep look into the SHOPPER model, and finally showed how the SHOPPER architecture could be translated to TensorFlow. Our results showed that meaningful embeddings could be extracted from our model and potentially be used to optimize the couponing efforts of a grocery retailer. Our methods and model could potentially be used in other retail settings as well.
Appendix
Random Utility Model
In the main body we briefly touched on the Random Utility Model. Here we provide more detail on the model and its interpretation.
Let $U_{tc}$ represent the utility a customer receives from choosing item $c$ on trip $t$ and $C$ represent the full set of alternatives ($c = 1, 2, ... ,C$; with $C\geq2$) the customer can choose from.
The customer then chooses item $c$ from the set of alternatives that provides the highest utilities. The customer chooses item $c$ such that $U_{tc} > U_{tc'} \; \forall \: c \neq c' $. Therefore the probability that the customer chooses a specific alternative can be written as $Prob(U_{tc} > U_{tc'} \; \forall \: c \neq c')$. Plugging in our utility function from before (equation 3) results in the following expression:
$P_c = p(\Psi(c, y_{t, i-1}) + \epsilon_{t,c} > \Psi(c', y_{t, i-1}) + \epsilon_{t,c'}, \; \forall \: c \neq c') $
Using the derivation from Train (2009) and the assumption of i.i.d error terms that follow a Gumbel distribution we can show that the probability of choosing item $c$ can be described using a softmax function.
$p(y_{ti} = c | \mathbf{y}_{t, i-1}) = \frac{exp\{\Psi(c, \mathbf{y}_{t, i-1})\}}{\displaystyle \sum_{c' \notin y_{t, i-1}}exp\{\Psi(c', \mathbf{y}_{t, i-1})\} } $
To calculate the probability item $c$ is chosen we exponentiate the customer's utility in trip $t$ with respect to item $c$ and divide that by the sum of all other utilites raised to base $e$. Keen observers will note that this is simply a softmax function over all possible items. This can be difficult to costly to calculate, so an alternate method is used instead, see below.
Estimating a Complex Softmax (Noise Contrastive Estimation)
From the shopper’s utility maximization problem, we see that the probability of a shopper selecting an item takes the form of a softmax function (see above). This function, however, is difficult to compute, due to the denominator. The denominator is a sum over all of the other items that are available except for the one that we are predicting on. In our case, it is a sum over approximately 35 000 items. One can imagine that each weight update requires a recalculation of the denominator, making the problem computationally difficult.
We then look to a technique developed by Gutman and Hyvärinen and modified by Mikolov et al. in the seminal word2vec paper (Mikolov et al., 2013). A similar problem, with an expensive softmax function, also occurs in natural language processing. Consider how word2vec generates its embeddings. When predicting the next word in a sentence, word2vec has to compare the probability of the target word to the probability of every other word in the dictionary. As the size of the vocabulary often contains tens of thousands of words, this becomes infeasible to calculate. To get around this problem, word2vec generates a noise sample, consisting of a set of words from the vocabulary that are not the next word in the sentence. It then becomes a binary classification problem between the correct word and “noisy” words.
The intuition of this method is that a good model should be able to discriminate between the actual data and data generated from a known noise distribution. If the model can tell the difference between actual data and generated noise, then it must have learned some underlying properties of the data. One can think of this as ‘learning by comparison’ (Gouws, S., 2016).
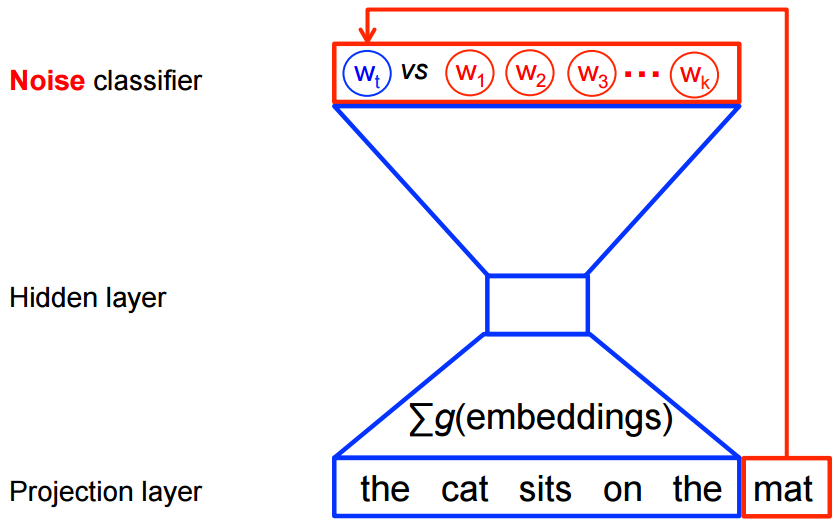
We apply a similar strategy with our sampling procedure. The optimal number of negative samples required for training is not clear. Further research is required to determine that number.
References
Ruiz, F. J. R., Athey, S., Blei, D. M. (2017) SHOPPER: A Probabilistic Model of Consumer Choice with Substitutes and Complements. Annals of Applied Statistics. https://arxiv.org/abs/1711.03560
Gopalan, P., Hofman, J. and Blei, D. M. (2015). Scalable recommendation with hierarchical Poisson factorization. In Uncertainty in Artificial Intelligence.
Rudolph, M., Ruiz, F. J. R., Mandt, S. and Blei, D. M. (2016). Exponential Family Embeddings. In Advances in Neural Information Processing Systems.
Iyengar, S. S. and Lepper, M. R. (2000). When Choice is Demotivating: Can One Desire Too Much of a Good Thing?. Journal of Personality and Social Psychology, Vol. 79, No. 6, 995-1006
Koren, Y., Bell, R., Volinsky, C. (2009) Matrix Factorization Techniques for Recommender Systems. IEEE Computer, 42(8):30–37
Nevo, A. (1998). Measuring Market Power in the Ready-To-Eat Cereal Industry. Food Marketing Policy Center Research Report No. 37
Molnar, F. J., Hutton, B., and Fergusson, D. (2008) Does analysis using “last observation carried forward” introduce bias in dementia research? Canadian Medical Association Journal, 179(8):751–753
Mcfadden D. (1978) Modeling the Choice of Residential Location. Transportation Research Record
Train K. E. (2009) Discrete Choice Methods With Simulation. Cambridge University Press. Ch 3, 34-75
Serrano, L. How Does Netflix Recommend Movies? Matrix Factorization. https://www.youtube.com/watch?v=ZspR5PZemcs (accessed Nov 2019)
McInnes, L., Healy, J., and Melville, J. (2018) UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction https://arxiv.org/abs/1802.03426
Gouws, S. (2016) Training Neural Word Embeddings for Transfer Learning and Translation. Phd Dissertation Stellenbosch University, Ch 3
Titsias, M. K. (2016). One-vs-Each Approximation to Softmax for Scalable Estimation of Probabilities. In Advances in Neural Information Processing Systems
Price Elasticity and Airfares: Analysing the Low Cost Long Haul Opportunity. https://www.partners.skyscanner.net/price-elasticity-a-long-haul-low-cost-opportunity-awaits/thought-leadership Skyscanner (accessed Dec 2019)
Mikolov, T., Chen, K., Corrado, G., Dean, J. (2013) Efficient Estimation of Word Representations in Vector Space. https://arxiv.org/abs/1301.3781
Salem, M. Market Basket Analysis with R. http://www.salemmarafi.com/code/market-basket-analysis-with-r/ (accessed Jan 2020)
Grenier, E. Survival Guide to German Supermarkets. https://www.dw.com/en/survival-guide-to-german-supermarkets/a-46312578 (accessed Jan 2020)
Jolliffe, I. (2011). Principal Component Analysis. In Lovric M. (eds) International Encyclopedia of Statistical Science. Springer, Berlin, Heidelberg
Lloyd, S. (1982). Least squares quantization in PCM. In IEEE Transactions on Information Theory, Vol. 28, No. 2, 129-137