By Seminar Information Systems (WS18/19) | February 8, 2019
Text Classification with Hierarchical Attention Networks
How to assign documents to classes or topics
Authors: Maria Kränkel, Hee-Eun Lee - Seminar Information System 18/19
After reading this blog post, you will know:
- What text classification is and what it is used for
- What hierarchical attention networks are and how their architecture looks like
- How to classify documents by implementing a hierarchical attention network
Introduction
Imagine you work for a company that sells cameras and you would like to find out what customers think about the latest release. Ratings might not be enough since users tend to rate products differently. Nowadays, you will be able to find a vast amount of reviews on your product or general opinion sharing from users on various platforms, such as facebook, twitter, instagram, or blog posts. As you can see, the number of platforms that need to be operated is quite big and therefore also the number of comments or reviews. So, how can you deal with all of this textual data and gain important insights from it?
Outline
- Introduction
- Text Classification
- Applications
- Literature Review
- Text Classification with Hierarchical Attention Networks
- News Classification
- Take Away
Text Classification
Evaluating all of the textual data manually is very time consuming and strenuous. A more efficient way to extract important information is text classification.
Text classification is a fundamental task in natural language processing. The goal is to assign unstructured documents (e.g. reviews, emails, posts, website contents etc.) to one or multiple classes. Such classes can be review scores, like star ratings, spam vs. non-spam classification, or topic labeling.
Essentially, text classification can be used whenever there are certain tags to map to a large amount of textual data. To learn how to classify, we need to build classifiers which are obtained from labeled data. In this way, the process of examining information becomes automated and thus simpler.
Applications
Text classification finds a variety of application possibilities due to large amount of data which can be interpreted.
By topic labeling every kind of assigning text to topics or categories is meant. This can also include unstructured texts. The main goal is to extract generic tags. Topic labeling is the most important and widest used application of text classification. It has a few sub-applications:
- Marketing: The ‘new’ marketing has moved from search engines to social media platforms where real communication between brands and users take place. Users do not only review products but also discuss them with other users. With text classification, businesses can monitor and classify users based on their online opinions about a product or brand. Based on this, trends and customer types (e.g. promoters or detractors) can be identified.
- Reviews: With text classification businesses can easily find aspects on which customers disagree with their services or products. They do not have to go through low rating reviews by themselves but can detect categories in which their product did or did not satisfy.
- Tagging content: Platforms, like blogs, live from publications of many people or pool products from other websites. So, if these are not tagged thoroughly in the first place, there might be the need to tag these texts or products in order to simplify navigation through the website. User experience is improved by this application too. In addition, good classified and tagged websites are more likely to appear in search engines like Google.
Mentioning Google: If you’re using Gmail, your emails are already automatically filtered and labeled by Google’s text classification algorithms.
Another application is sentiment analysis. Imagine again how different customers might rate a product. Someone could be disappointed about one single feature and consequently give it a low star rating although they like the overall product. Or ratings might be low due to bad customer service whilst the product itself is satisfying. Text classification helps to identify those criteria.
Sentiment analysis predicts the sentiment towards a specific characteristic on the base of text classification. This not only finds economic application, but also for social and political debates.
Text classification is already used for simpler applications, such as filtering spam. Also, a team of Google invented a method called Smart Replies in 2016. This method takes emails as inputs, identifies the sentiment or topic of the mailed text and automatically generates short, complete responses.
Literature Review
For our implementation of text classification, we have applied a hierarchical attention network, a classification method from Yang et al. from 2016. The reason they developed it, although there are already well working neural networks for text classification, is because they wanted to pay attention to certain characteristics of document structures which have not been considered previously.
But before going deeper into this, let’s have a look at what others did:
The basis of all text classification problems lies in the so-called Information Retrieval (IR) methods which were first developed in the early 1970s. These first methods were unsupervised which means that they try to find information from a given text document without classifying it or assigning labels to it in any kind.
Basic algorithms for IR are:
- Bag of Words (BoW): represents texts by frequency of appearing words
- Term Frequency / Inverse Document Frequency (TF-IDF): sets term frequency and inverse document frequency in ratio and in this way represents texts by relevance of appearing words
- N-grams: a set of co-occurring words (e.g. names)
Here you can see the most important steps in unsupervised text classification:
Unsupervised
| Year | Authors | Method Characteristics | Paper |
|---|---|---|---|
| 1971 | Jardine, van Rijsbergen | Clustering keywords of similar texts | [The Use of Hierarchic Clustering in Information Retrieval](https://www.researchgate.net/publication/220229653_The_Use_of_Hierarchic_Clustering_in_Information_Retrieval) |
| 1974 | Salton et al. | Ranking words in accordance with how well they are able to discriminate the documents | [A Theory of Term Importance in Automatic Text Analysis.](https://eric.ed.gov/?id=ED096987) |
| 1983 | Salton, McGill | SMART - First text representations with vectors | [Introduction to Modern Information Retrieval](http://www.information-retrieval.de/irb/ir.part_1.chapter_3.section_6.topic_6.html) |
| 1992 | Cutting et al. | SG - Scattering text to few clusters, manual gathering to sub-collections | [Scatter/Gather: A Cluster-based Approach to Browsing Large Document Collections](https://www-users.cs.umn.edu/~hanxx023/dmclass/scatter.pdf) |
| 1998 | Zamir, Etzioni | Suffix Tree - Phrases shared between documents - First IR for web search engines | [Web Document Clustering: A Feasibility Demonstration](https://homes.cs.washington.edu/~etzioni/papers/sigir98.pdf) |
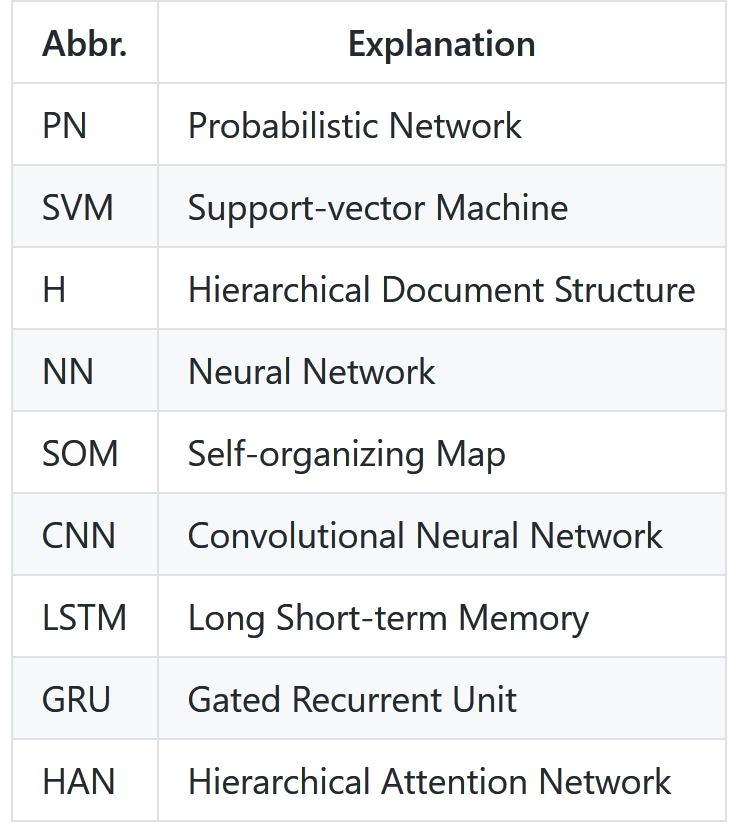
Find all listed abbreviations in the following table:

With the improvement of the user-friendliness and related spread of internet usage, automated classification of growing numbers of data became important. Several supervised respectively semi-supervised methods (where the class information are learned from labeled data) are shown in the next table.
**(Semi-) Supervised**
| Year | Method | Authors | Characteristics | Paper |
|---|---|---|---|---|
| 1995 | PN | Makoto, Tokunaga | Clustering by maximum Bayesian posterior probability | [Hierarchical Bayesian Clustering for Automatic Text Classification](http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=BE17EC88A0C9DB576DA0E36C70F54EC3?doi=10.1.1.52.2417&rep=rep1&type=pdf) |
| 1999 | PN | Nigam et al. | Improving learned classifiers with Expectation Maximization and Naive Bayes | [Text Classification from Labeled and Unlabeled Documents using EM.](http://www.kamalnigam.com/papers/emcat-mlj99.pdf) |
| 1998 | SVM | Joachims | Binary classifying, representation with support-vectors | [Text Categorization with Support Vector Machines: Learning with Many Relevant Features.](http://web.cs.iastate.edu/~jtian/cs573/Papers/Joachims-ECML-98.pdf) |
| 2004 | SVM | Mullen, Collier | Classifying with SVM and unigrams | [Sentiment analysis using support vector machines with diverse information sources](http://www.aclweb.org/anthology/W04-3253) |
| 2005 | SVM-H | Matsumoto et al. | SVM + unigrams and bigrams, Sentence dependancy sub-trees, word sub-sequences | [Sentiment Classification Using Word Sub-sequences and Dependancy Sub-trees](https://link.springer.com/content/pdf/10.1007%2F11430919_37.pdf) |
| 1994 | NN | Farkas | NN + Thesaurus -> First weighted, dictionary-based relations | [Generating Document Clusters Using Thesauri and Neural Networks](https://vdocuments.site/ieee-proceedings-of-canadian-conference-on-electrical-and-computer-engineering-58e24c154d826.html) |
| 1996 | NN-SOM | Hyötyniemi | Competitive learning instead of error-correction (e.g. backpropagation), Mapping to reduced dimensions | [Text Document Classification with Self-Organizing Maps](http://lipas.uwasa.fi/stes/step96/step96/hyotyniemi3/) |
| 1998 | NN-SOM-H | Merkl | SOM on hierarchical document levels | [Text classification with self-organizing maps: Some lessons learned](https://www.sciencedirect.com/science/article/pii/S0925231298000320) |
| 2014 | CNN | Johnson, Zhang | CNN on word order instead of low-dimensional word vectors | [Effective Use of Word Order for Text Categorization with Convolutional Neural Networks](https://arxiv.org/pdf/1412.1058.pdf) |
| 2014 | CNN | Kim | Simple CNN with static vectors on top of pre-trained word vectors | [Convolutional Neural Networks for Sentence Classification](https://arxiv.org/pdf/1408.5882.pdf) |
| 2014 | CNN-char | dos Santos, Zadrozny | Semantic word information with CNN on character level | [Learning Character-level Representations for Part-of-Speech Tagging](http://proceedings.mlr.press/v32/santos14.pdf) |
| 2015 | LSTM | Tai et al. | LSTM on tree-structured networks | [Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks](http://aclweb.org/anthology/P15-1150) |
| 2015 | C-LSTM | Zhou et al. | CNN for higher-level representations, LSTM for sentence representations | [A C-LSTM Neural Network for Text Classification](https://arxiv.org/pdf/1511.08630.pdf) |
| 2015 | CNN/LSTM-GRU | Tang et al. | CNN / LSTM for sentence representation, GRU for semantic information | [Document Modeling with Gated Recurrent Neural Network for Sentiment Classification](http://ir.hit.edu.cn/~dytang/paper/emnlp2015/emnlp2015.pdf) |
| 2016 | HAN | Yang et al. | GRU and attention on contexts on hierarchical document level | [Hierarchical Attention Networks for Document Classification](https://www.cs.cmu.edu/~diyiy/docs/naacl16.pdf) |
Nigam et al.(1999) show in their probabilistic method that text classification improves significantly when learning from labeled data.
Support Vector Machines (SVM) use support vectors as classifier. Here, Matsumoto et al.(2005) involve hierarchical structure by creating sentence representations.
Since we use a neural network, the comparison with other neural networks is a priority to us. Of course, there are several different implementations of convolutional and recurrent neural networks; selected steps during the development of NN for text classification are mentioned in the table.
It is already common use to combine layers of CNN and RNN. Several approaches successfully covered the hierarchical structure of documents (e.g. Zhou et al., 2015) and computed importance weights. Still, contexts of words and sentences, including the changing meanings in different documents, are new to text classification tasks and find a first solution with HAN.
Text Classification with Hierarchical Attention Networks
Contrary to most text classification implementations, a Hierarchical Attention Network (HAN) also considers the hierarchical structure of documents (document - sentences - words) and includes an attention mechanism that is able to find the most important words and sentences in a document while taking the context into consideration. Other methods only return importance weights resulting from previous words.
Summarizing, HAN tries to find a solution for these problems that previous works did not consider:
-
Not every word in a sentence and every sentence in a document are equally important to understand the main message of a document.
-
The changing meaning of a word depending on the context needs to be taken into consideration. For example, the meaning of the word “pretty” can change depending on the way it is used: “The bouquet of flowers is pretty” vs. “The food is pretty bad”.
In this way, HAN performs better in predicting the class of a given document.
To start from scratch, have a look at this example:

Here, we have a review from yelp that consists of five sentences. The highlighted sentences in red deliver stronger meaning compared to the others, and inside, the words delicious and amazing contribute the most in attributing the positive attitude contained in this review. This example reproduces our aforementioned statement about HAN, which we also intuitively know: not all parts of a document are equally relevant to gain the essential meaning from it.
Architecture of Hierarchical Attention Networks
This is how the architecture of HANs looks like:
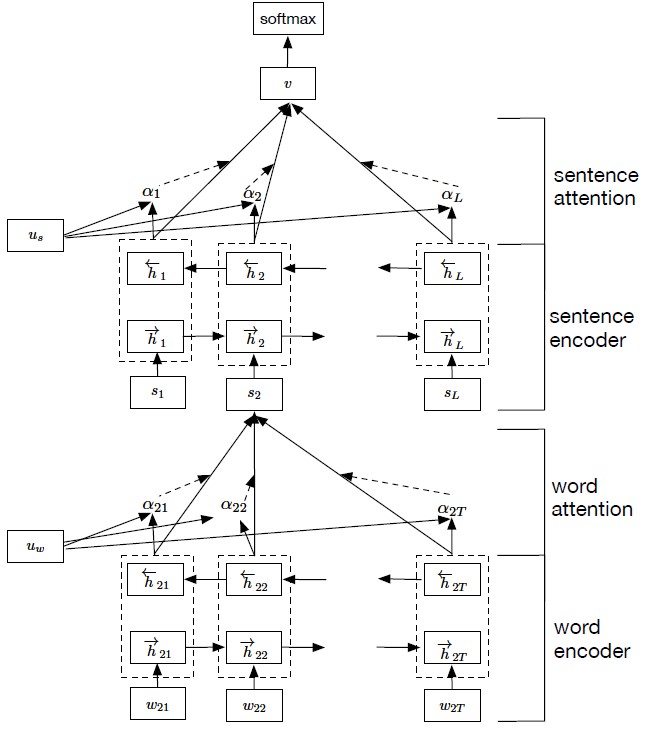
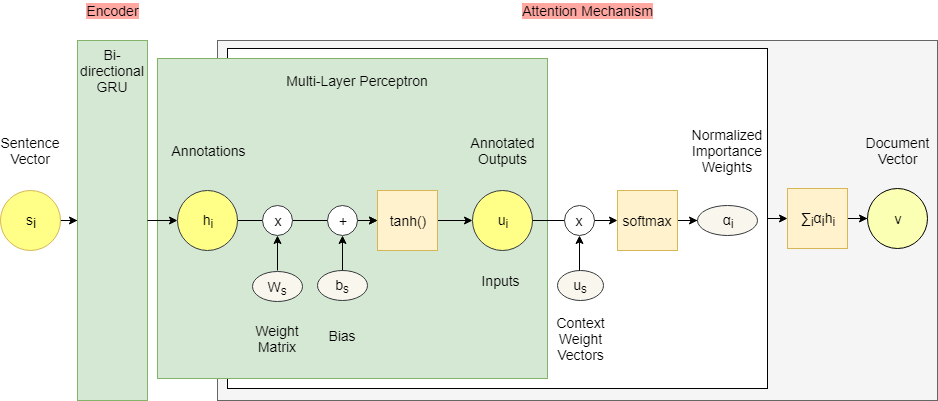
First, the network considers the hierarchical structure of documents by constructing a document representation by building representations of sentences and then aggregating those into a document representation.
**Sentence representations** are built by first encoding the word of a sentence and then applying the attention mechanism on them resulting in a *sentence vector*.
**Document representation** is built in the same way, however, it only receives the sentence vector of each sentence of the document as input.
To understand the different processes of the HAN architecture better, we took the structure a little bit apart and provide a different perspective. Take a look:
The same algorithms are applied twice: First on word level and afterwards on sentence level.
The model consists of
-
the encoder which returns relevant contexts, and
-
the attention mechanism, which computes importance weights of these contexts as one vector.
Word Level

![]()
- As input we have the structured tokens **$w_{it}$** which represent the word i per sentence t. We do not keep and process all words in a sentence. Learn more about that in the section data preprocessing.
- Since the model is not able to process plain text of the data type string, the tokens run through an Embedding layer which ‘assigns’ multidimensional vectors **$W_{e}$** **$w_{it}$** to each token. In this way, words are represented numerically as **$x_{it}$** as a projection of the word in a continuous vector space.
- There are several embedding algorithms: the most popular ones are word2vec and GloVe. It is also possible to use pre-trained word embeddings, so you can accelerate your model training.
Word Encoder
- These vectorized tokens are the inputs for the next layer. Yang et al.(2016) use a Gated Recurrent Network (GRU) as an encoding mechanism.
- As a short reminder: In an RNN, states are ‘remembered’ to ensure we can predict words depending on previous words. A GRU has a so-called ‘hidden state’ which can be understood as a memory cell to transfer information. Two gates decide whether to keep or forget information and with this knowledge, to update the information that should be kept. If you are interested in learning more about GRU, have a look at another blog post of this semester about LSTMs and GRUs.
- The purpose of this layer is to extract relevant contexts of every sentence. We call these contexts annotations per word.
Note that in this model, a bidirectional GRU is applied to get annotations of words by summarizing information from both directions resulting in a summarized variable **$h_{it}$**.
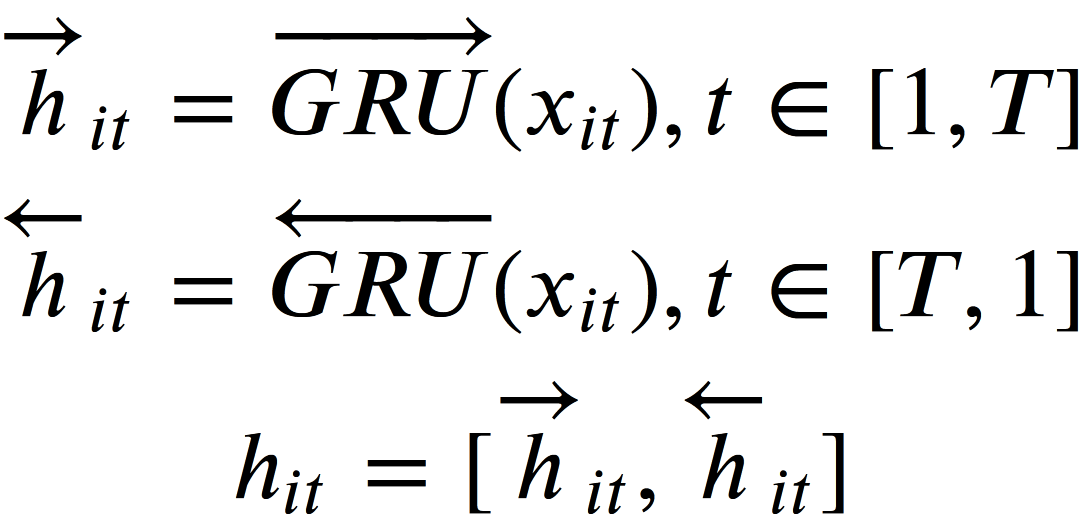
Word Attention
- The annotations **$h_{it}$** build the base for the attention mechanism which starts with another hidden layer, a one-layer Multilayer Perceptron. The goal is to let the model learn through training with randomly initialized weights and biases. Those ‘improved’ annotations are then represented by **$u_{it}$**. Furthermore, this layer ensures that the network does not falter with a tanh function. This function ‘corrects’ input values to be between -1 and 1 and also maps zeros to near-zero.
![]()
-
Our new annotations are again multiplied with a trainable context vector **$u_{w}$** and normalized to an importance weight per word **$\alpha_{it}$** by a softmax function. The word context vector **$u_{w}$** is randomly initialized and jointly learned during the training process.
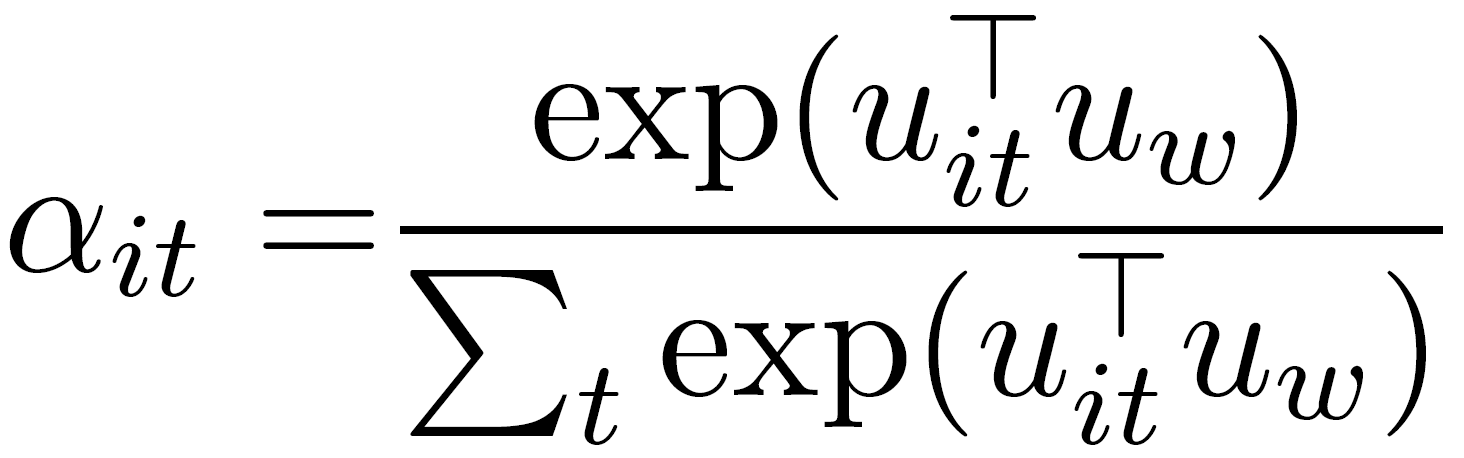
-
The sum of these importance weights concatenated with the previously calculated context annotations is called sentence vector **$s_{i}$**
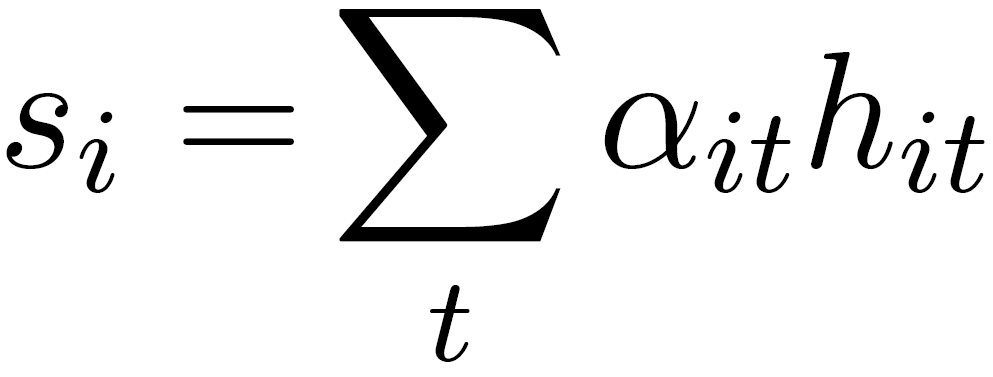
Sentence Level
- Then the whole network is run on sentence level with basically the same procedure as on word level, but now we focus on the sentence i. Of course, there is no embedding layer as we already get sentence vectors **$s_{i}$** from word level as input.
Sentence Encoder
- Contexts of sentences are summarized with a bidirectional GRU by going through the document forwards and backwards.
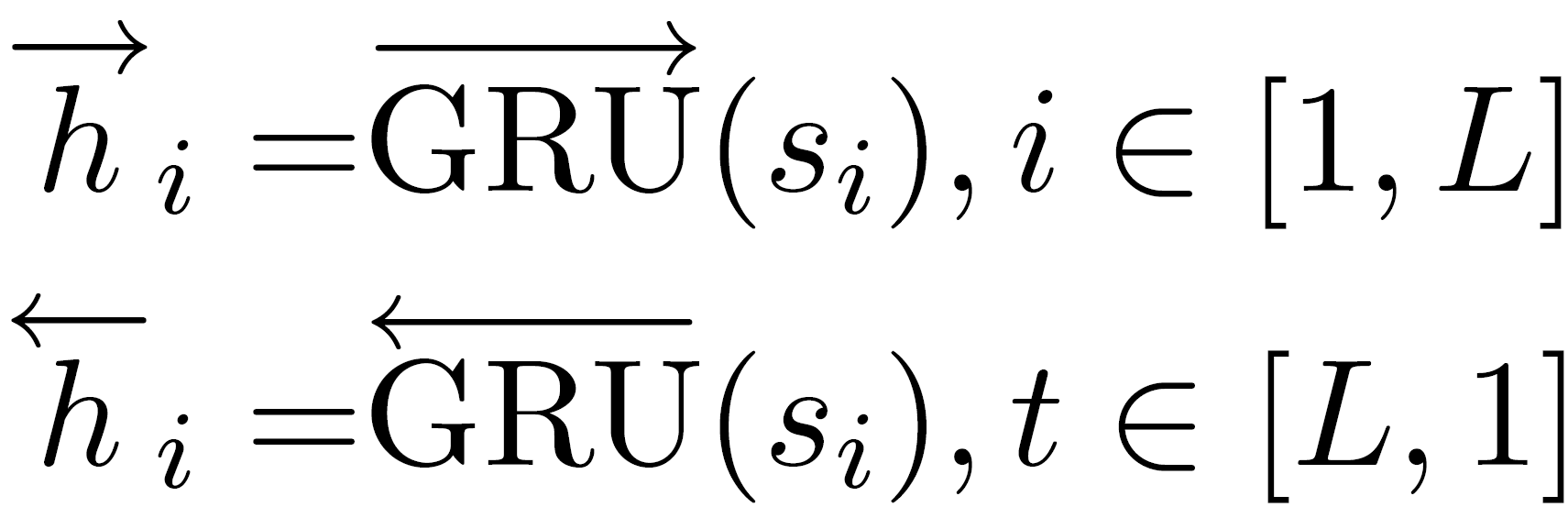
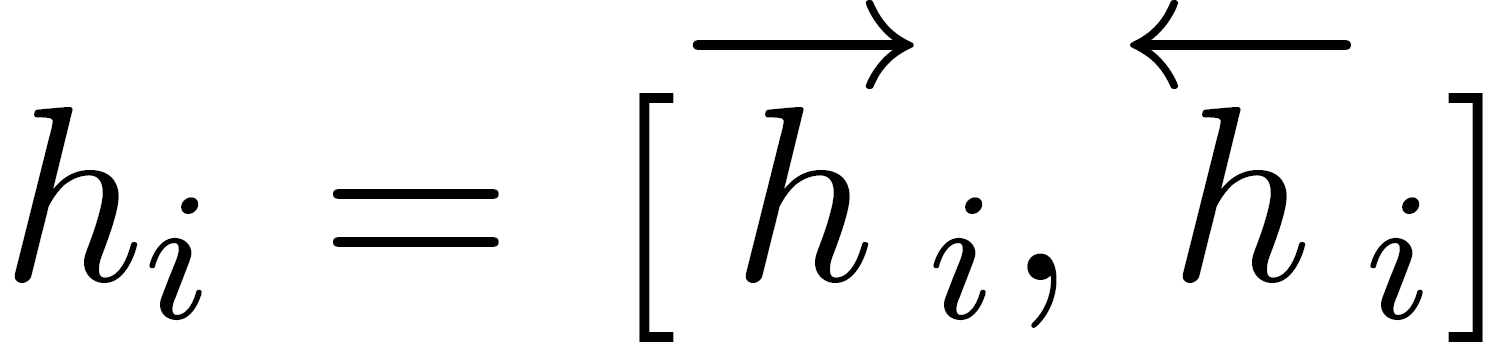
Sentence Attention
- Trainable weights and biases are again randomly initialized and jointly learned during the training process.
- The final output is a document vector $v$ which can be used as features for document classification.
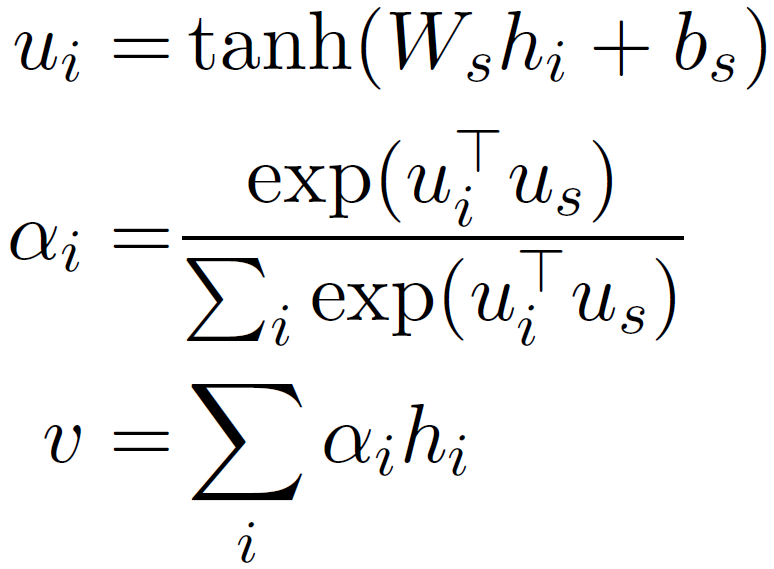
Implementation
We use the ‘high-level neural networks API’ Keras which is extremely useful for deep learning problems. We recommend to install it in an own python environment.
Data Preprocessing
To demonstrate the application of HANs, we use Amazon reviews for electronic data which are publicly available here. This data set consists of nearly 1.7 million reviews. As the model learns through training, it is highly important to have data sets with a large number of observations. Nevertheless, a million reviews would take us days to train on, so we set the number of reviews to keep equal to 100,000.
Words have to be lemmatized to ensure that not every single typo or related term is handled by itself. Additionally, so-called stop words are filtered out. In our case, they are mainly prepositions like as or to that do not contribute to the meaning of the text. Have a look at function cleanString.
After that, we can tokenize the given sentences. We set the maximum number of words to keep equal to 200,000.
We keep 62,837 tokens.
A cleaned review looks like this. First, we have the original review and underneath the review without stop words and with lemmatization:
For the vectorization of our tokens we use one of GloVe’s pre-trained embedding dictionaries with 100 dimensions which means that one word will be represented by 100 values in a matrix. As mentioned before, this accelerates our training. We match our tokens with the pre-trained dictionary and filter out words that appear rarely (mostly due to spelling mistakes). As you can see, reviewers for our chosen products do not pay attention to correct spelling. Therefore, we can only remain 20,056 words to proceed. This will influence the performance of our model. But we will come to this later.
For a better comprehension of what those embeddings mean, have a closer a look at an example sentence and a single token. Great is described by 100 values in vector spaces computed by for instance nearest neighbors.
In the last step of data preprocessing, we want to set a train, validation and test data set. For that, we define the function split_df which ensures that all sets are balanced, hence they have the same ratio for each class as the full data set. Without this predefined grouping by star rating, it could happen that the model only trains on the most occurring rating.
#### Attention Mechanism
Before we can concatenate the layers of the network in Keras, we need to build the attention mechanism. Keras has a class ‘Writing your own Keras layer'. Here you are given some useful functions to implement attention.
The class AttentionLayer is successively applied on word level and then on sentence level.
-
init initializes variables from a uniform distribution. Also, we set supports_masking = True because the network needs fixed input lengths. Therefore, every input gets a mask with the length equal to the maximum input length initialized with 0. Then, the mask will be padded with “1” at each position where the input holds values. Both padded input sequence and appropriate mask run through the network; to avoid that the network will recognize every input with the same length because of padding, the mask is used to check whether the input is just padded or actually has maximum length.
-
build defines the weights. We set len(input_shape) == 3 as we get a 3d tensor from the previous layers.
-
call builds the attention mechanism itself. As you can see, we have *$h_{it}$*, the context annotations, as input and get the sum of importance weights, hence, the sentence vector *$s_{i}$*, as output. In between, the current variable is reduced by the last dimension and expanded again because masking needs a binary tensor.
Model
Congrats, you made it through a huge mass of theoretical input. Now, let’s finally see how the model performs. Some last little hints:
-
The layers have to be combined on word and sentence level.
-
TimeDistributed applies to all word level layers on each sentence.
-
We want to have an output dimensionality of GRU equal to 50 because running it forwards and backwards returns 100 dimensions - which is the dimensionality of our inputs.
-
Dropout is a regularizer to prevent overfitting by turning off a number of neurons in every layer. 0.5 gets a high variance, but you can play around with this as well as with other parameters.
-
Dense implements another layer for document classification. The document vector runs again with the learned weights and biases through a softmax function.
We train the model throughout a relatively small number of 7 epochs since our input data are already pre-trained and could overfit after too many epochs. Also, the batch size of 32 works with a large number of inputs due to our large data set. Note that you have to train reviews $x$ against labels $y$ (in this case the 5-star ratings).
Model evaluation is with 69 % quite high how a comparison with the results from Yang et al.(2016) as well as from others shows (see table below).
Also, history plots show that the training data set perform pretty well. Still, this is unfortunately not supported by the validation data set. This might be because of the small number of words we proceeded with after the embedding layer which filtered out almost 70 % of all tokens due to misspelling. An improvement could be created with an even smaller batch and epoch size, or with a better, less mistaken data set.
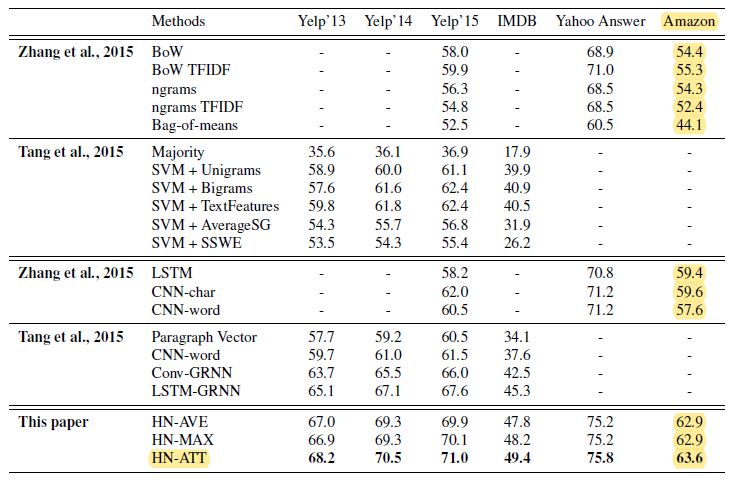 Note: HN-AVE and HN-MAX refer to hierarchical networks with averaging and max-pooling methods. HN-ATT refers to hierarchical attention networks as described in this blog.
Note: HN-AVE and HN-MAX refer to hierarchical networks with averaging and max-pooling methods. HN-ATT refers to hierarchical attention networks as described in this blog.
This is how one of our 5-star reviews looks like that our model has predicted. The categorization of the review as a 5-star rating works quite well in this case:
News Classification
To further demonstrate the attention mechanism, we also implemented the HAN on news articles to be able to classify them into categories, as well as to gain short summaries of articles by extracting the most important sentences using sentence attention weights. News articles are particularly interesting within this context because the hierarchical architecture can fully exploit the length of the document, compared to shorter documents, such as tweets.
We used a publicly available data set from the British Broadcasting Corporation (BBC) which contains 2225 news articles from the BBC news website from 2004-2005. The news articles are sorted after five different categories: business, entertainment, politics, sport, and tech.
Parameters
As news articles tend to be longer than product reviews, we first calculated the average number of words in each sentence and the average number of sentences in each document.
Subsequently, we adjusted the parameters and increased the maximum number of sentences in one document and the maximum number of words in each sentence.
HAN Model
The data preprocessing steps are the same as for the Amazon data set. Hence, we skip right to our HAN Model which looks as follows. Merely, the parameters have changed here.
We get the following results for our training, validation, and test set:
Compared to the Amazon data set, the BBC data set exhibits a much higher accuracy rate. This is probably due to several facts:
- News articles are in general much longer than product reviews, and therefore the HAN can exploit this and gain more information.
- Also, news articles have no grammar and spelling mistakes, while product reviews written by users just burst from them. Grammar and spelling mistakes lead to misinterpretation of words and thus loss of information.
- Another aspect is that the categorization classes of the BBC data set are much easier to distinguish, whereas the star rating categorization of Amazon is very subjective and it is quite hard to draw a straight line between different categories.
Input new articles
To access newly released articles from BBC, we need to scrape the BBC website and save the title and text which is then cleaned, as described in the preprocessing, and subsequently converted to a sequence of numbers (see: embeddings.)
Sentence Attention Model
Now, we need to build a new model to be able to extract the attention weights for each sentence. This is to identify the five most important sentences within a news article to put them together and create a short summary.
To extract the attention weights that lie within the hidden layer of the attention mechanism, we build a separate model instead of using the complete attention model of the HAN. The sentence attention model encompasses the processes from the input of the HAN to the output of the attention layer on sentence level which is where we basically cut it off. We constructed sent_coeffs so that we not only gain the attention output from our model but also the attention weights. Thus, we redefined the model in order to obtain the attention weights for each sentence which we use to create a summary of the news article.
Word Attention Model
Additionally, we want to extract the usually hidden word attention weights as well for which we need to build another model. The words with the most attention serve as a good overview or framework for the article.
Output
This is how the final output for the BBC article that we scraped from the website looks like.
Our HAN model has successfully predicted the category of the article as entertainment. Moreover, we were able to extract the attention weights with the sentence and word attention models. Hence, we gained the five most important words which actually provide a good overview of the article and could be used as additional tags. The summary of the article which we obtained through the sentence attention weights, also shows a quite well-working abstract.
As a comparison, you can look at the full text below.
The information of the articles could then be saved in a new database. The words with the most attention could be used as new tags for the database and could facilitate search navigation if also implemented on websites. This might be useful for news agencies that have to deal with many articles a day and need to hold on to information for research purposes.
Take Away

As you can see, the hierarchical attention network is a well performing instrument to create some pretty cool text classification solutions. We hope this blog post - regardless of its mass of information - gives you an understanding of how to use HAN. The most relevant points to remember are:
- the hierarchical structure of documents (document - sentence - word),
- paying attention to contexts of sentences and words,
- by considering changing contexts, HAN performs better for classification problems.